五一前几天错峰,闲来无事,在 GPT 5.5 和 Claude Opus 4.7 的帮助下,尝试完善 Lua 生态的测试代码覆盖率统计。重构 cluacov。最终拿到了一份分支覆盖率数据:https://shansan.top/cluacov/,这数据对应的测试代码为 https://github.com/yeshan333/cluacov/tree/master/e2e
一、 引言
代码覆盖率是衡量测试质量的基础度量之一。行覆盖率(line coverage)回答“这一行是否被执行过”,但它无法回答一个更关键的问题:“这个条件分支的两条路径是否都被覆盖了?”
考虑这样的 Lua 代码:
1 | if a or b or c then |
行覆盖率只能告诉你 if 所在行是否被执行。但 a or b or c 在编译为字节码时,Lua 编译器会为每个操作数生成一条独立的 TEST 指令——总共 3 条,每条都是一个独立的分支决策点(这是 or 短路求值的编译实现:若 a 为真则直接跳转,否则继续检查 b,依此类推)。仅凭行命中数据,无法区分“只有 a 为真”和“三个条件都被测试过”这两种情况。
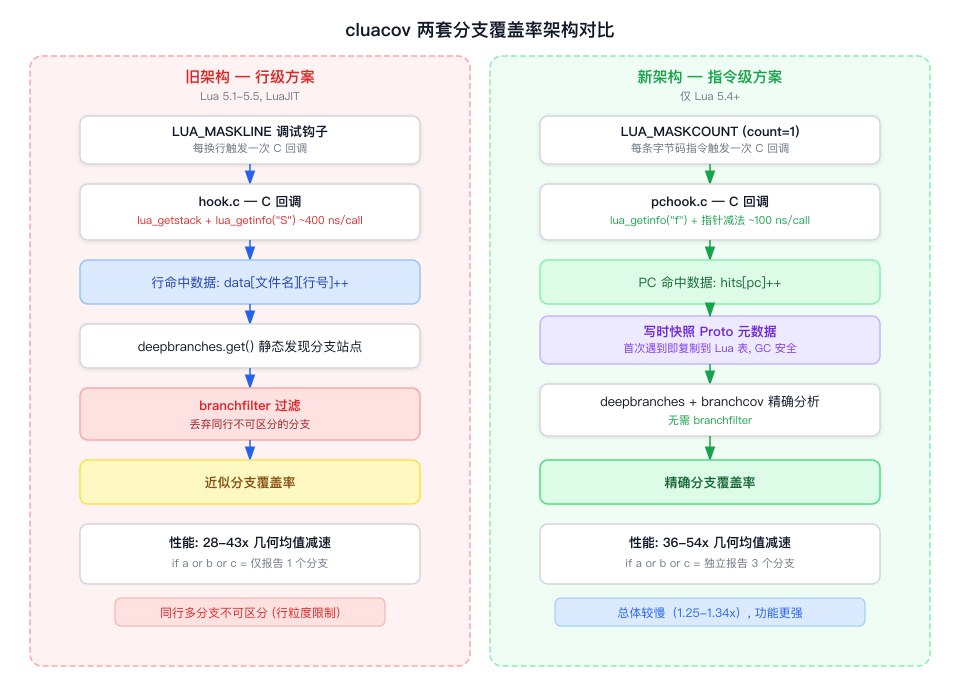
cluacov 是 LuaCov(Lua 生态中最主流的代码覆盖率工具,纯 Lua 实现)的 C 扩展。最初版本的 cluacov 仅用于提供行级覆盖率的性能加速,本身并不支持分支覆盖。为了填补这一空白,我们设计并实现了两套分支覆盖率方案:一套基于行级调试钩子的近似方案(兼容 Lua 5.1 到 5.5 及 LuaJIT),另一套基于指令级计数钩子的精确方案(仅支持 Lua 5.4+)。两者的设计差异,本质上反映了 Lua 调试接口在不同粒度下的能力边界。
二、 Lua 背景知识
本节为不熟悉 Lua 内部机制的读者提供必要的背景。如果你已经了解 Lua 的编译模型和 C API,可以直接跳到“快速上手”。
2.1 编译与执行模型
Lua 是一门解释执行的语言。源代码首先被编译为字节码(bytecode),然后由一个基于寄存器的虚拟机(VM)逐条解释执行。这类似于 Python 的 .pyc 或 Java 的 .class,但 Lua 的 VM 使用寄存器而非操作数栈。
每个 Lua 函数编译后在 VM 内部对应一个 C 结构体 Proto(prototype),它存储了函数运行所需的全部静态信息:
| Proto 字段 | 含义 |
|---|---|
code[] |
字节码指令数组,VM 实际执行的内容 |
lineinfo[] |
每条指令对应的源码行号(用于调试和错误报告) |
source |
源文件名字符串,如 "@test.lua" |
linedefined |
函数定义的起始行号 |
sizecode |
字节码总条数 |
p[] |
嵌套子函数的 Proto 指针数组 |
k[] |
常量表(字符串、数字等字面量) |
一个 Lua 文件加载后,最外层是一个 Proto,文件中定义的每个 function 又是一个子 Proto(通过 p[] 嵌套)。loadfile("foo.lua") 编译文件并返回最外层 Proto 对应的闭包(closure)。cluacov 的分支分析就是通过读取 Proto.code[] 来扫描字节码中的分支指令。
2.2 调试钩子
Lua 提供了 C 级别的调试钩子(debug hook)API,允许在特定事件发生时调用用户提供的 C 回调函数:
1 | lua_sethook(L, callback, mask, count); |
mask 参数控制触发条件:
| 掩码 | 触发时机 |
|---|---|
LUA_MASKCALL |
每次函数调用时 |
LUA_MASKRET |
每次函数返回时 |
LUA_MASKLINE |
每次执行到新的源码行时 |
LUA_MASKCOUNT |
每执行 count 条指令时 |
覆盖率工具正是利用这些钩子来拦截程序执行并记录命中数据。行覆盖率使用 LUA_MASKLINE,而 cluacov 的指令级方案巧妙地将 LUA_MASKCOUNT 的 count 设为 1,实现每条指令触发。
2.3 Lua C API 基础
Lua 和 C 之间通过一个虚拟栈通信。C 代码不直接操作 Lua 对象,而是通过 lua_push* 压入值、lua_to* 读取值、lua_rawgeti/lua_rawseti 访问表元素等 API 间接操作。本文代码中出现的几个关键概念:
lua_State:Lua 执行上下文(线程),所有 API 调用的第一个参数CallInfo:VM 调用栈中的一帧,保存了当前函数的执行状态(包括savedpc——下一条要执行的指令地址)- 注册表 (Registry):一个只有 C 代码能访问的全局 Lua 表,用于存储不想暴露给 Lua 层的私有数据。cluacov 用注册表存储每个 Proto 的命中计数表
2.4 GC 与 __gc 元方法 (Finalizer)
Lua 使用自动垃圾回收(Mark-and-Sweep)。当一个对象不再被引用时,GC 会回收它的内存。Lua 支持 __gc 元方法(在英文文档中也称为 终结器/Finalizer):在对象被垃圾回收前触发调用,用于清理资源。
关键问题:当 Lua 解释器关闭时(lua_close),所有对象在 luaC_freeallobjects 阶段被释放,__gc 元方法在此阶段被触发。此时,对象的释放顺序是不可预测的——当元方法 A 执行时,元方法 A 所依赖的对象 B 可能已经被提前释放了。这正是 cluacov 采用“首次遇到时即时备份”设计的原因:在 Proto 还活着的时候提前把数据拷贝备份出来。
2.5 Lua 版本生态
Lua 主线(PUC-Rio)有多个主要版本,内部结构在版本间有显著变化:
| 版本 | 特点 |
|---|---|
| Lua 5.1(2006) | 最广泛部署的版本,LuaJIT 兼容此版本 |
| Lua 5.2(2011) | 引入 goto、移除 setfenv |
| Lua 5.3(2015) | 原生整数类型、位运算 |
| Lua 5.4(2020) | 泛型 for 改进、CallInfo 布局重构 |
| Lua 5.5(2025) | 全局变量声明、增量式主 GC、只读循环变量 |
| LuaJIT 2.1 | 高性能 JIT 编译器,API 兼容 5.1 |
Proto 结构、CallInfo 布局、操作码编码在这些版本间都有差异。cluacov 需要针对每个版本做适配——这也是为什么代码中有大量条件编译和 vendor 头文件。
三、 快速上手
3.1 指令级覆盖率(推荐,Lua 5.4+)
最简单的使用方式是通过 cluacov.runner,它封装了完整的采集和报告生成流程:
1 | lua -lcluacov.runner your_program.lua |
程序退出后,当前目录下会生成两个文件:
luacov.stats.out— LuaCov 兼容的行命中数据lcov.info— 包含行覆盖率和分支覆盖率的 LCOV 报告
使用 genhtml 生成 HTML 报告:
1 | genhtml lcov.info --output-directory html --branch-coverage |
如果需要手动控制采集生命周期(loadfile 编译 Lua 文件并返回一个可调用的函数对象):
1 | local pchook = require("cluacov.pchook") |
3.2 行级覆盖率(Lua 5.1-5.3 / LuaJIT)
在不支持指令级钩子的环境下,使用传统的 LuaCov 行命中数据配合 deepbranches 静态分析:
1 | lua -lluacov your_program.lua |
然后用 deepbranches.get 发现分支点,与行命中数据交叉比对来估算分支覆盖率。由于行级钩子的粒度限制,需要经过 branchfilter.lua 过滤无法区分的同行分支。
四、 核心概念:分支点的静态发现
无论使用哪套方案,分支覆盖率的第一步都相同:通过 deepbranches.get(func) 静态分析字节码,找出函数中所有的分支点。
deepbranches.get 接受一个 Lua 函数,遍历其 Proto 结构中的字节码数组,识别五类分支指令:
| 类型 | 字节码 | 源码对应 |
|---|---|---|
test |
OP_TEST, OP_TESTSET, OP_EQ, OP_LT 等 |
if、elseif、and、or、比较运算 |
loop |
OP_FORLOOP |
数值 for 循环的继续/退出 |
loop-entry |
OP_FORPREP(仅 Lua 5.4+) |
数值 for 循环的初始进入 |
iterator |
OP_TFORLOOP |
泛型 for 迭代器的耗尽判断 |
assert |
OP_CALL |
Lua assert(...) 语句的成功与失败分支 |
每个分支点恰好有两个目标——两条可能的执行路径。目标按 PC(程序计数器)升序排列,不按语义方向(“真/假”)排列。
1 | local deepbranches = require("cluacov.deepbranches") |
deepbranches.get 会递归遍历嵌套函数的 Proto 链(proto->p[]),一次调用即可获取整个文件中所有函数的分支点。
五、 行级方案(旧架构)的实现
5.1 原生 LuaCov 为什么只有行覆盖率?
在深入研究分支方案前,我们先看原生 LuaCov 的运作方式。原生 LuaCov 是一套纯 Lua 实现的工具,其数据采集完全基于 Lua 的 debug.sethook 调试钩子,并使用 "l" (line) 模式:
1 | debug.sethook(runner.debug_hook, "l") |
原生 LuaCov 仅支持行覆盖率,原因在于:
- Lua 接口的能力限制:Lua 标准调试库(
debug)仅向用户层暴露了line(行)、call(调用)、return(返回)和count(指令数计数)事件,并未向 Lua 提供类似“当前指令 PC 值”或“执行的操作码”等更细粒度的机制。 - 调试钩子的物理边界:在行触发模式(
LUA_MASKLINE)下,回调函数仅能获得当前正在执行的“行号”,根本无法感知或区分这一物理行内到底执行了哪条具体的字节码指令。 - 巨大的运行时性能开销:原生的 LuaCov 回调函数完全基于纯 Lua 编写。这意味着每当程序运行一行,就要触发一次 Lua 层面的函数调用,由此引入了 200x~300x 级别的运行开销。在 Lua 用户层已经极为缓慢的前提下,根本无法支持更细粒度的高频指令监听。
我们实现的旧架构(行级近似方案),正是保留了这种“行级数据”的统计模式,但在 C 语言层面重写了 Hook 以提升性能(即 hook.c ),然后利用静态分析的分支行号进行估算对齐。其计算逻辑如下:
deepbranches.get(func)静态发现所有分支点及其两个目标的行号- 检查每个目标行是否有命中数据(
line_hits[target.line] > 0) - 两个目标都命中 → covered;一个命中 → partial;都未命中 → uncovered
5.2 行级粒度的根本限制
问题出在第 2 步:行命中数据的粒度是“行”,而非“指令”。当同一行包含多条分支指令时,它们共享同一个命中计数。
以 if a or b or c then 为例,Lua 编译器会生成 3 条 TEST 指令,都对应同一行源码。假设 a 为真,程序直接跳入 then 体。此时第 2、第 3 条 TEST 根本未执行,但行命中数据显示 if 所在行被命中了——3 条 TEST 的命中状态无法区分。
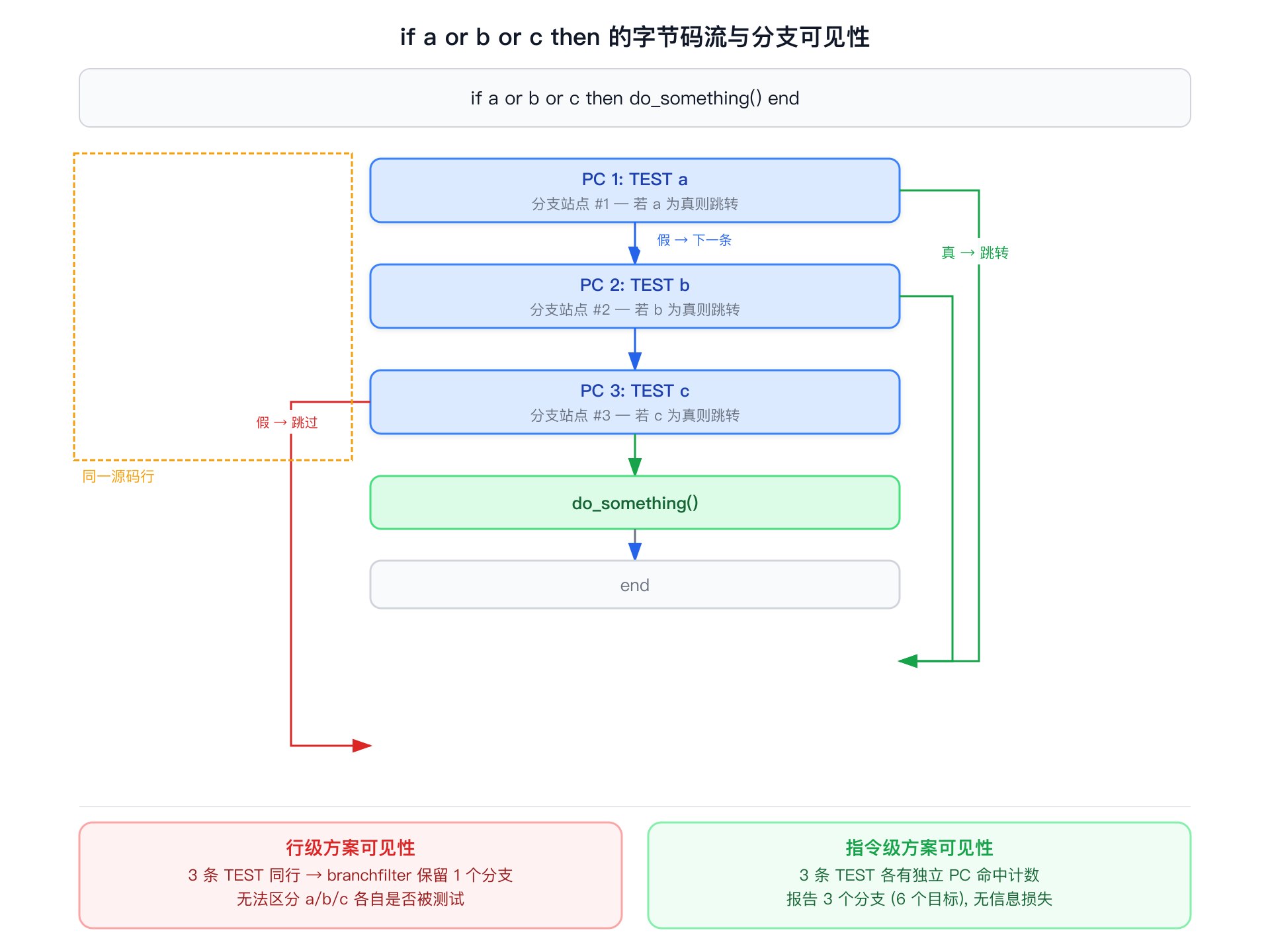
这不是 cluacov 的设计缺陷,而是 Lua 调试接口的能力边界:LUA_MASKLINE 钩子按行触发,Lua 官方不提供指令级的回调机制。C/gcov 之所以能做到精确的分支覆盖率,是因为编译器在编译期就插入了弧计数器(arc counters),每条分支指令有独立的计数。Lua 的调试钩子没有这个能力。
5.3 branchfilter:过滤不可区分的分支
既然同行多分支不可区分,旧架构就需要把这些分支过滤掉,避免产生误导性的报告。branchfilter.lua 的过滤规则:
对于同一行上有多个分支点的情况,只保留两个目标行都不在本行的分支。同时,对目标行对相同的分支做去重。
这条规则有明确的语义基础。以 if a and b 为例,编译为两条 TEST:第一条的两个目标中,一个指向本行的第二条 TEST(短路跳转),另一个也在本行(顺序执行);只有最后一条 TEST 的两个目标分别指向 then 体和 else 体(都不在本行),因此只有它被保留。这保证了保留下来的分支是可以通过行命中数据真正区分的。
以下为核心逻辑的简化版(省略了跳过计数 skipped):
1 | function M.filter(branches) |
过滤后的分支数量通常远少于原始分支数量。对于 if a or b or c then,3 条 TEST 只保留 1 条;对于 for i = 1, n,FORPREP 和 FORLOOP 的目标行对相同,去重后只保留 1 条。
六、 指令级方案(新架构)的实现
6.1 核心设计:每条指令一次回调
新架构的核心突破在于使用 LUA_MASKCOUNT 计数钩子(count=1),使得 C 回调在每条字节码指令执行时触发。这不是 Lua 标准调试 API 中的“指令钩子”(Lua 并未提供 LUA_MASKPC),而是利用计数钩子的一种技巧:将计数间隔设为 1,效果上等同于每条指令触发。
pchook.c 中的 l_start 函数注册钩子(若传入 tick 配置则额外注册 LUA_MASKLINE 用于定期保存):
1 | lua_sethook(L, pc_hook, LUA_MASKCOUNT, 1); // 基础模式 |
钩子回调 pc_hook 在每次触发时读取当前函数的 Proto 指针和程序计数器(PC),然后在一个 Lua 表中递增该 PC 的命中计数。以下仅展示 count 事件的核心处理逻辑(省略了 tick 模式下的 LUA_HOOKLINE 事件处理):
1 | static void pc_hook(lua_State *L, lua_Debug *ar) { |
关键的技术细节在于 PC 的获取方式:通过 ar->i_ci(CallInfo 指针)访问 ci->u.l.savedpc,它是 Lua 5.4 的 CallInfo 结构中保存的下一条待执行指令的地址。按照 Lua 解释器的惯例(luaG_traceexec 中先执行 pc++; ci->u.l.savedpc = pc; 再调用钩子),savedpc 始终指向下一条指令而非刚刚执行的指令。因此 savedpc - proto->code 得到的是“next-instruction PC”,而非当前指令的偏移量。这个内部结构在 Lua 5.4 之前的版本中有不同的布局,所以 pchook 仅支持 Lua 5.4+。
这个惯例产生了一个重要的双层契约:
| 层 | hits[pc] 的含义 | 是否需要校正 |
|---|---|---|
存储层(pc_hook) |
“savedpc 指向此处时计数钩子触发” | 否——直接存储 |
分支读取层(branchcov.lua) |
与 target.pc(跳转目标 PC)直接兼容 |
否——target.pc 也是 next-instruction PC |
行聚合层(collect_line_hits_recursive) |
需要回退到实际执行指令的行号 | 需要 pc - 1 |
行聚合层的 pc - 1 校正对应 Lua 源码中的 pcRel 宏(src/ldebug.h):
1 |
如果省略这个校正,每个函数体的第一条可执行语句(如 local t = obj.field)会显示 hits = 0,后续行会被错误地多计。这是因为 PC 0 永远不会作为 hits 表键出现(没有“上一条指令”能产生 savedpc == 0),而每条指令的命中被归因到了下一条指令的行号。
6.2 Proto 元数据的惰性拷贝快照:GC 安全性设计
pchook.c 最精妙的设计在于它如何处理 Proto* 指针的生命周期问题。
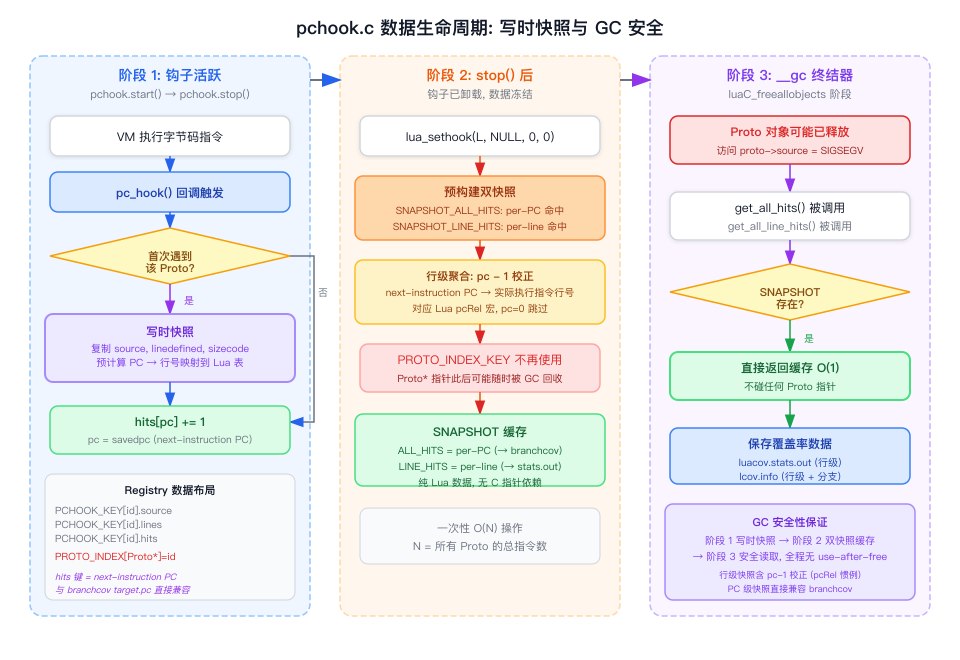
cluacov.runner 注册了 __gc 元方法(参见前文“GC 与 __gc 元方法 (Finalizer)”)来确保程序退出时自动保存覆盖率数据。但 __gc 回调在 luaC_freeallobjects 阶段触发,此时 Proto 对象可能已被释放。如果报告生成函数试图读取 proto->source 或 proto->lineinfo,就是一次释放后使用 (use-after-free),直接导致 SIGSEGV。
解决方案是惰性拷贝快照(snapshot on first execute,即首次遇到该 Proto 时立即将其元数据复制备份为纯 Lua 表):在钩子第一次遇到某个 Proto 时,立即将所有后续需要的元数据复制到纯 Lua 表中,此后再也不需要访问 Proto 指针。
以下代码经过轻微简化以突出核心逻辑(源码中的变量声明和 NULL 判断略有展开):
1 | static void materialize_proto_entry(lua_State *L, const Proto *proto) { |
Registry 中的数据布局:
1 | PCHOOK_KEY[entry_id] = { |
PROTO_INDEX_KEY 是唯一持有 Proto* 的结构。l_stop 在关闭钩子后立即预构建两种聚合快照——SNAPSHOT_ALL_HITS_KEY(每个 PC 的命中数据,供 branchcov.lua 使用)和 SNAPSHOT_LINE_HITS_KEY(每行的命中数据,供 runner.lua 生成 luacov.stats.out 使用),将聚合结果缓存;后续从 __gc 中调用 get_all_hits 或 get_all_line_hits 时直接返回缓存,无需再碰 Proto。这意味着 pchook 现在同时输出 PC 级数据(用于分支覆盖率)和行级数据(用于行覆盖率),一次采集兼顾两种粒度。
6.3 branchcov:指令级分支覆盖率分析
有了针对每个 PC 的命中数据,branchcov.lua 的分析逻辑非常直接:
1 | function M.analyze(func) |
Proto 的标识使用 linedefined:sizecode 组合键,而非 Proto 指针,这与惰性拷贝快照的设计一致。每个分支的每个目标都有独立的命中计数,if a or b or c then 的 3 条 TEST 指令各自产生 2 个目标,总共 6 个分支目标,每个都可以独立判断是否被执行。
因此,指令级方案不需要 branchfilter。
七、 行为细节与常见误区
7.1 目标 PC 的排序不代表语义方向
deepbranches.get 返回的 targets[1] 和 targets[2] 按 PC 升序排列,不是 targets[1] = true 分支、targets[2] = false 分支。这是一个稳定的排序规则,但如果你试图根据索引判断“哪个是 true 路径”,结果会出错。覆盖率分析不需要知道语义方向,只需要知道“两条路径是否都被执行过”。
7.2 共享目标 PC 的语义
多条分支指令可能共享同一个目标 PC。if a or b or c then do_something() end 中,3 条 TEST 的 true 目标都指向 do_something() 的第一条指令。当 a 为真时,该目标 PC 被执行,但只有第一条 TEST 的 true 路径真正被“走过”。然而指令级 PC 的命中数据只能说明“该 PC 是否被执行过”(指令覆盖率),不能说明“是从哪条分支到达的”(边覆盖率)。这是指令级方案的一个已知近似——在绝大多数实际场景中,这个近似足够准确。
7.3 get_hits 要求同一函数对象
pchook.get_hits(func) 中的 func 必须是在 pchook.start() 活跃期间实际执行过的那个函数对象。钩子通过 Proto* 指针标识函数。如果你用 loadfile 重新加载同一个文件,得到的是一个新的 Proto 对象,与钩子记录的不匹配,get_hits 会返回空数据。
7.4 Lua 5.4 的行号编码
Lua 5.4 对调试信息的行号编码做了重大改变:从 5.3 及之前版本的 lineinfo[pc] 直接映射,变成了 abslineinfo 基线索引表 + lineinfo[pc] 差分编码 (Delta Encoding) 的两级结构。这是为了压缩大函数的调试信息体积(差分编码的每个条目只需 1 字节,而绝对行号需要 4 字节)。deepbranches.c 和 pchook.c 中都需要实现 getbaseline + 差分累加来还原行号:
1 | static int luaG_getfuncline(const Proto *f, int pc) { |
7.5 savedpc off-by-one:一个容易误修的陷阱
pchook.c 中 collect_line_hits_recursive 的行号映射代码包含一个 pc - 1:
1 | if (pc <= 0) continue; |
这个 -1 不是索引基准转换(从 0 开始与从 1 开始的起始位置转换),而是 Lua 解释器惯例的校正——将 next-instruction PC 回退到实际执行的指令。这个区别曾被误读为“多余的偏移”并被移除(commit fc9499f),导致每个函数体的第一条可执行语句在 LCOV 报告中显示 DA:<line>,0(尽管该行实际被执行了多次),后续在 commit 5050dd0 中修复。教训是:PC 值旁边的 -1 几乎从来不是基数转换,而是解释器惯例调整。Lua 自身的 pcRel 宏是权威参考。
7.6 为什么有些 end 行有命中次数,有些却留空
阅读 HTML 覆盖率报告时经常遇到的困惑:
1 | 11 : 1 : end ← 函数 end: 可执行,命中 1 次 |
这不是 cluacov 的 bug。一行源码会被标记为“可执行”,当且仅当 Lua 编译器确实为这一行发射了至少一条字节码指令(该指令的 lineinfo 指回这一行)。end 关键字本身不是语句,它能否进入行表完全取决于编译器是否有控制流或清理指令需要锚定到该行:
end 的位置 |
锚定的字节码 | 是否可执行 |
|---|---|---|
函数体的 end |
OP_RETURN0(隐式 return nil) |
总是 |
if/elseif/else 的 end |
无(控制流已由 OP_JMP 处理) |
永不 |
do ... end 的 end |
无 | 永不 |
repeat 的 until 行 |
条件测试 + 回跳 OP_JMP |
总是 |
for 循环 end(简单,无闭包捕获) |
无(OP_FORLOOP 绑到 for 行) |
否 |
for 循环 end(带 break + 需 close 的局部变量) |
OP_TFORLOOP(5.5 把它绑到 end 行) |
是 |
for 循环 end(循环体捕获循环变量的闭包) |
OP_CLOSE(关闭 upvalue) |
是 |
while 循环 end(简单) |
无(回跳绑到循环体最后一行) | 否 |
while 循环 end(需要关闭闭包) |
OP_CLOSE |
是 |
直觉理解:函数 end 对应真实的运行时动作(RETURN);if-end 和 do-end 是纯语法标记;循环 end 是条件性的——只有当编译器在作用域退出时确实有事可做(关闭 upvalue),才会有指令绑到这一行。可以用 luac -l -p file.lua 反汇编验证。
八、 内部实现机制
8.1 deepbranches.c 的字节码遍历
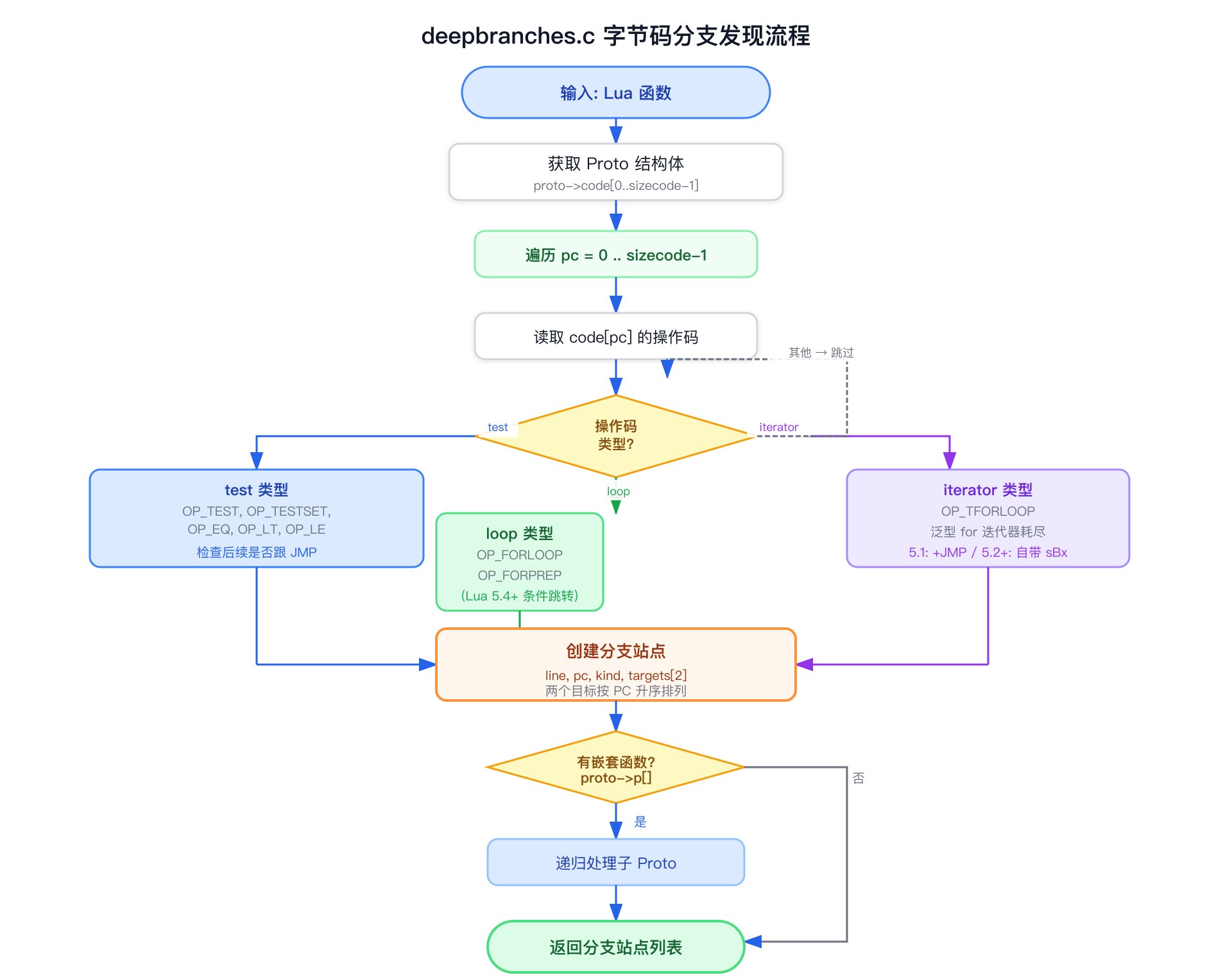
deepbranches.c 的核心是一个线性扫描:遍历 proto->code[0..sizecode-1],对每条指令检查操作码是否属于分支指令类型。
对于 test 类分支,识别模式在所有版本中保持一致:“TEST 指令 + 紧跟的 JMP 指令”。TEST 本身不跳转,它设置跳转条件,紧随的 JMP 执行实际跳转。两个目标分别是 pc+2(不跳转,跳过 JMP)和 JMP 的目标地址。Lua 5.4 改变了 TEST 指令的参数编码方式(条件标志从 C 参数改为 k 参数),但 TEST+JMP 双指令模式不变。deepbranches.c 统一使用检查 is_test_opcode 后是否紧跟 OP_JMP 的方式来检测所有 test 类分支(包括 OP_TEST、OP_TESTSET、OP_EQ、OP_LT 等),适用于 Lua 5.1 到 5.5 全版本。
对于循环分支,各版本的处理差异较大:
- Lua 5.4+:
OP_FORPREP变成了条件指令(判断初始条件是否满足),产生loop-entry类型分支;OP_FORLOOP使用Bx参数编码回跳偏移 - Lua 5.1-5.3:
OP_FORLOOP使用sBx参数编码回跳偏移 - Lua 5.1:
OP_TFORLOOP后跟OP_JMP;Lua 5.2+:OP_TFORLOOP自带sBx跳转
这些差异通过条件编译处理,这也是 deepbranches.c 需要 vendor 各版本 Lua 的 lobject.h 和 lopcodes.h 头文件的原因。
8.2 pchook.c 的两阶段聚合
为了在高频回调场景下保持性能,pchook.c 采用了两阶段设计:
Phase 1(l_stop 时):钩子停止后立即遍历 PCHOOK_KEY 的所有条目,预构建两种聚合表:SNAPSHOT_ALL_HITS_KEY(针对每个源文件、每个 PC 的命中数据,供 branchcov.lua 分支分析)和 SNAPSHOT_LINE_HITS_KEY(针对每个源文件、每行的命中数据,供 runner 输出 luacov.stats.out)。这是一次 O(N) 的操作(N = 所有 Proto 的总指令数),但只执行一次。行级聚合中,每个 hits 表键(next-instruction PC)会通过 pc - 1 校正后映射到实际执行指令的源码行号。
*Phase 2(l_get_all_ 时)**:检查对应的 SNAPSHOT_*_KEY 是否已有缓存。有则直接返回(O(1));无则实时计算。缓存路径专为 GC finalizer 设计——此时钩子已停止,数据不会再变化,缓存是安全的。
聚合函数全程使用绝对栈索引(Lua C API 通过虚拟栈与 C 代码通信,栈索引可以是从栈底计数的正数“绝对索引”,或从栈顶计数的负数“相对索引”):
1 | static void aggregate_all_hits(lua_State *L, int result_idx) { |
在涉及多层栈操作的 C/Lua 胶水代码中,相对索引(如 -3)在 push/pop 后会失效,而绝对索引不会。这是一个在实际开发中容易犯错的点——pchook.c 的第一版重写就因为相对索引导致了崩溃。
8.3 钩子快速路径的摊还代价
push_hits_for_proto 在首次遇到某个 Proto 时执行快照(O(sizecode)),后续访问只需通过 PROTO_INDEX_KEY 查找 entry_id 再读取 hits 表(O(1))。由于每个 Proto 只快照一次,整个采集过程的快照总代价是 O(S)(S = 所有 Proto 的字节码总长度),而钩子本身的每次调用是 O(1)。在程序执行数百万条指令的典型场景中,快照代价被充分摊还。
8.4 assert 分支的特殊处理(虚拟 PC 与动态求差)
在 Lua 字节码中,assert(condition) 并非专门的跳转/控制流分支指令,而是表现为普通的函数调用:通常由环境/全局变量或 Upvalue 加载指令(如 OP_GETGLOBAL / OP_GETTABUP / OP_GETUPVAL)配合 OP_CALL 构成。这为分支覆盖率的设计带来了两个挑战:
- 静态识别:为了确定
OP_CALL指令是否调用了assert,deepbranches.c在线性扫描字节码时,如果遇到OP_CALL,会沿着其目标寄存器向前搜索定义该寄存器的指令。如果是对全局或环境表的常量字符串"assert"检索,便将其识别为assert分支点。- Lua 5.2/5.3 的 RK 编码特殊性:在 Lua 5.2 和 5.3 中,
OP_GETTABUP的键值可能编码为 RK 形式(由BITRK标记的常量索引),在静态匹配时必须先使用ISK验证并以INDEXK提取真实常量表索引,否则将无法识别,此细节在 CI 矩阵的 5.2/5.3 版本中已被修复。
- Lua 5.2/5.3 的 RK 编码特殊性:在 Lua 5.2 和 5.3 中,
- 分支路径与命中数的统计:
assert有两条截然不同的执行分支:- 成功路径 (Success path):
assert返回并继续执行,它对应于OP_CALL指令的下一条指令物理地址pc + 1。 - 失败路径 (Failure path):
assert抛出错误阻断控制流(如抛出异常或导致程序崩溃/终止),在当前的被测函数中并没有可继续执行的下一条物理字节码。
- 成功路径 (Success path):
为了在报告中展现失败分支,我们采用了一种**“虚拟 PC + 动态求差”**的设计:
- 虚拟负数 PC:我们在静态分析中人为为失败路径构建了一个虚拟负数 PC
-(pc + 1),用于标识该assert的失败路径目标。 - 动态求差计算:既然失败路径无法触发
pc_hook的物理执行,我们就在branchcov.lua和runner.lua中通过统计差值计算它:failure_hits = call_hits - success_hits其中,call_hits是OP_CALL指令物理位置(pc)的命中数;success_hits是指令成功返回处(pc + 1)的物理命中数。如果call_hits > success_hits,说明有若干次调用由于断言失败中断而没有走到下一行,这个差值便作为失败分支的虚拟命中数记录到lcov.info的BRDA记录中。
这一设计在保持原生虚拟机零侵入的前提下,优雅地支持了 assert 场景下非正常控制流的分支覆盖率采集。
- 动态求差污染的边界场景 (Contamination of Dynamic Differencing):值得注意的是,该求差公式成立的一个隐含假设是——指令
pc + 1(成功返回处)的执行只能从pc处的OP_CALL正常返回到达。如果pc + 1物理位置同时也是其他控制流(例如其他地方的goto、break或if跳转)的汇合点(Merge Point),那么success_hits就会被其他路径执行次数污染(导致其数据虚高,即便我们有小于0置0的保护,统计出的failure_hits也会因此偏低)。在绝大多数常规编码风格中,assert之后紧跟的通常是正常的顺序执行代码,但在存在复杂跳转汇合的结构中,这是该估算算法的一个已知理论局限。
九、 性能与特性分析
9.1 性能代价
指令级钩子在每条 VM 指令上触发 C 回调,事件量是行级钩子的 3-7 倍。直觉上这应该更慢,但实际基准测试显示两者的性能差距取决于硬件和工作负载。在三台不同机器上的几何均值减速因子:
| 机器 | cluacov C 钩子 | pchook | 总体胜者 |
|---|---|---|---|
| Xeon 8269CY(Linux CI) | 28.1x | 36.1x | cluacov C 钩子(快 1.28 倍) |
| Xeon 8369B(Linux) | 36.9x | 49.6x | cluacov C 钩子(快 1.34 倍) |
| Apple M4 Pro(macOS) | 43.3x | 54.0x | cluacov C 钩子(快 1.25 倍) |
cluacov C 钩子在所有测试机器上总体胜出(几何均值快 1.25-1.34 倍),两者性能处于同一量级。纯 Lua 的 luacov 钩子开销最大(231-299x)。
关键在于 per-call 成本与事件量的权衡。cluacov C 行级钩子每次回调需要调用 lua_getstack + lua_getinfo(L, "S", ...) 来解析源文件名,单次成本约 400 ns。而 pchook 只调用轻量的 lua_getinfo(L, "f", ar) 获取函数值,然后直接从 CallInfo.u.l.savedpc 读取 next-instruction PC(一次指针减法),通过预建的整数索引查找元数据,跳过了昂贵的源文件解析,单次成本仅约 100-130 ns。但 pchook 的事件量是行级钩子的 3-7 倍,在所有测试机器上(包括 Xeon 8269CY、Xeon 8369B 和 M4 Pro),pchook 更高的事件量在几何均值层面都抵消了其 per-call 优势。pchook 仅在紧密循环工作负载上胜出(指令/行比率低,约 3:1),而 cluacov C 钩子在递归和函数调用密集的代码上一致胜出(指令/行比率 3.5-7:1)。
9.2 内存开销
per-PC 模式需要为每个 Proto 的每条被执行指令维护一个 Lua 整数。对于一个 1000 行的 Lua 文件(假设编译为约 3000 条指令),额外的内存开销大约在几十 KB 量级。快照后的元数据(source 字符串、lines 表)也会占用额外空间,但因为是 Lua GC 管理的,不需要手动释放。
9.3 准确性的 trade-off
行级方案的准确性受限于过滤规则。过滤会丢弃同行的短路分支,导致报告中的分支总数少于实际分支数。对于 if a or b or c then,行级方案只报告 1 个分支(2 个目标),而指令级方案报告 3 个分支(6 个目标)。
指令级方案虽然更精确,但仍然是指令覆盖率而非边覆盖率——它知道某个 PC 是否被执行过,但不知道执行时是从哪条分支跳转过来的。在实际工程中,这个区别很少造成误判。
十、 两套方案的对比
| 维度 | 行级方案(hook.c) | 指令级方案(pchook.c) |
|---|---|---|
| Lua 版本 | 5.1-5.5, LuaJIT | 仅 5.4+ |
| 钩子类型 | LUA_MASKLINE |
LUA_MASKCOUNT(count=1);tick 模式下额外注册 LUA_MASKLINE |
| 数据粒度 | 行 | 字节码指令(PC)+ 行级聚合(双输出) |
| 复合条件 | 不可区分(if a or b or c = 1 个分支) |
独立计数(= 3 个分支) |
| 是否需要过滤 | 需要(branchfilter) | 不需要 |
| 性能开销 | 28-43x 几何均值(换行触发,~400 ns/call) | 36-54x 几何均值(每条指令触发,~100 ns/call);总体较慢但功能更强 |
| GC 安全性 | 天然安全(仅保存文件名与行号,无 Proto* 依赖) | 历史上有释放后使用 (use-after-free) 风险,已通过首次遇到时备份元数据解决 |
| 输出格式 | 需手动生成 LCOV | runner 自动生成 |
| 代码量 | ~550 行 C(hook.c 179 行 + deepbranches.c 375 行) | ~1190 行 C + Lua(pchook.c 1114 行 + branchcov.lua 76 行;deepbranches.c 共用) |
行级方案适合 Lua 5.1-5.3 或 LuaJIT 环境,或只需粗粒度覆盖率的场景。指令级方案适合 Lua 5.4+ 环境且需要精确分支覆盖率的场景,如安全关键系统的测试验证或 CI/CD 流水线中的覆盖率质量门禁。多平台基准测试表明 cluacov C 钩子在所有测试机器上的几何均值都快于 pchook(1.25-1.34 倍),但两者仍处于同一量级,因此方案选择应以功能需求为主导。
十一、 与相关技术的对比
11.1 与 LuaCov 原生方案的区别
LuaCov 本身只做行覆盖率。它没有分支分析能力,也不会输出 BRDA 记录。cluacov 的 deepbranches 和 pchook 是在 LuaCov 的行命中数据之上的增量能力。cluacov.runner 在输出 luacov.stats.out(LuaCov 兼容)的同时,额外输出 lcov.info(包含分支记录)。
11.2 与 C/gcov 的分支覆盖率对比
gcov 的分支覆盖率是编译器级别的精确实现:GCC 在编译期为每条分支指令插入弧计数器,运行时直接递增硬件级计数器,开销极低。gcov 提供的是真正的边覆盖率(edge coverage)——不仅知道某个基本块是否被执行,还知道从哪个前驱块到达。
cluacov 在 Lua 层面没有这个条件。Lua 是解释执行的,没有编译期插桩的机会。指令级钩子是运行时拦截,每次触发都有函数调用和表操作的代价。即便如此,cluacov 在 Lua 生态中已经是分支覆盖率能力最强的方案。
十二、 使用建议
适合使用 cluacov.runner(指令级方案)的场景:
- Lua 5.4+ 项目的 CI/CD 覆盖率采集
- 需要发现复合条件(
and/or)中未覆盖的子条件 - 需要生成带分支标注的 HTML 报告
适合使用行级方案的场景:
- 必须兼容 Lua 5.1-5.3 或 LuaJIT
- 只需粗粒度覆盖率,行级足够
不适合使用指令级钩子的场景:
- 生产环境的性能监控(两种 C 钩子的开销在 28-54x 量级,不适合生产环境)
- 需要边覆盖率语义的严格验证
常见错误用法:
- 在
pchook.stop()后用loadfile重新加载文件,然后传给get_hits——得到的是新 Proto 对象,无法匹配钩子数据 - 在 Lua 5.3 环境调用
pchook.start()——会直接报错 - 忘记在
.luacov中配置exclude规则,导致 cluacov 自身的模块也被采集
十三、 总结
cluacov 的分支覆盖率实现本质上是在 Lua 调试接口的能力边界内做到了最大化利用:行级钩子只能做到近似,通过过滤规则剔除不可区分的分支来保证报告的可信度;指令级钩子利用 LUA_MASKCOUNT 的每指令触发特性,配合 Proto 元数据写时快照解决了 GC 安全性问题,实现了无需过滤的精确分支覆盖率。两套方案是递进关系而非替代关系——前者保证了广泛兼容性,后者在 Lua 5.4+ 上提供了更高的精度。
附录:如何解读 LCOV 覆盖率报告
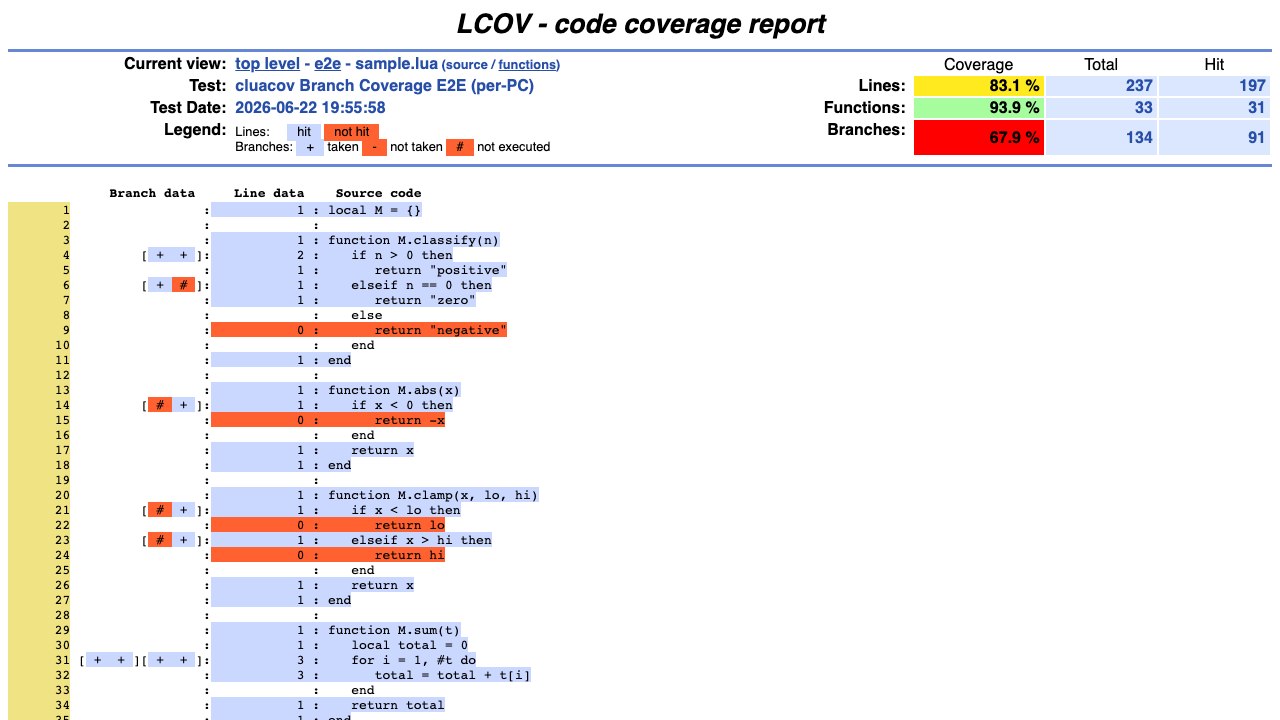
cluacov.runner 在程序退出时自动生成 lcov.info,这是标准的 LCOV 格式文件,可以直接被 genhtml 等工具消费。下图以真实输出片段为例,逐行解读每个字段的含义:

附录 A:LCOV 文件结构
每个被测源文件对应一段记录,由 TN(Test Name,测试名称)和 SF(Source File,源文件路径)开头、end_of_record 结尾。记录内包含四类覆盖率数据:
函数覆盖率:FN(Function Name,函数声明)格式为 FN:行号,函数名,声明函数位置;FNDA(Function Data,函数命中数据)格式为 FNDA:命中次数,函数名,记录调用次数。FNF(Functions Found,函数总数)/ FNH(Functions Hit,已调用函数数)是汇总。
分支覆盖率(cluacov 独有):BRDA(Branch Data,分支命中数据)格式为 BRDA:行号,站点ID,路径ID,命中次数,是核心记录。每个分支点(if、for、and/or 等)有两条路径(路径 0 和路径 1),命中次数为 - 表示该路径从未执行。BRF(Branches Found,路径总数)/ BRH(Branches Hit,已命中路径数)是汇总。
行覆盖率:DA(Data line,行命中数据)格式为 DA:行号,命中次数,记录每行执行次数。0 表示该行可执行但未被覆盖。LF(Lines Found,可执行行总数)/ LH(Lines Hit,已命中行数)是汇总。
附录 B:分支覆盖状态判定
对于同一个站点 ID 的两条 BRDA 记录:
- covered(完全覆盖):两条路径都有命中次数(如
BRDA:4,0,0,1+BRDA:4,0,1,1) - partial(部分覆盖):只有一条路径命中(如
BRDA:6,1,0,1+BRDA:6,1,1,-) - uncovered(未覆盖):两条路径都是
-(对应从未进入的代码块)
附录 C:生成 HTML 报告
1 | genhtml lcov.info --output-directory html --branch-coverage |
生成的 HTML 报告会用颜色标注每行的覆盖状态,分支用 [+ +](covered)、[+ -](partial)、[- -](uncovered)标记。这是 CI/CD 中最常用的覆盖率可视化方式。
下图展示了通过该命令生成的分支覆盖率 HTML 报告的直观效果(其中包含分支点命中情况与 [+ +] / [+ -] 详细标记):