
Sanitizer 全景:从编译插桩到硬件标签的内存安全检测演进
C 和 C++ 至今仍是操作系统内核、浏览器引擎、数据库等基础软件的主力语言。这些语言不提供自动内存管理,程序员直接操控指针和内存生命周期,由此产生的内存安全问题——越界访问、Use-After-Free、未初始化读取、数据竞争——是现实世界中最主要的安全漏洞来源。微软和 Google 的统计数据均表明,其产品中约 70% 的高危安全漏洞源自内存安全缺陷。
Sanitizer(内存安全动态检测工具)是 LLVM/GCC 工具链中一组动态检测工具的统称,通过编译时插桩和运行时检查,在程序执行过程中实时捕获内存错误。从 2012 年 AddressSanitizer 首次发布,到 ARM MTE 硬件原生标签检测,这一技术路线经历了从纯软件到软硬件协同的完整演进,形成了覆盖开发、测试、生产环境的多层防御体系。
范围说明:本文聚焦用户态 C/C++ 常见 sanitizer 及相关硬件/生产化方案,不展开内核侧的 KASAN、KMSAN、KCSAN 等变体。
核心工具与基本用法
Sanitizer 家族包含多个针对不同缺陷类型的独立工具。大多数工具通过编译器标志(-fsanitize=...)启用,无需修改源代码;也有部分工具(如 GWP-ASan、MTE)通过运行时配置或系统级参数启用,无需重新编译。
AddressSanitizer (ASan)
ASan 检测堆/栈/全局缓冲区越界访问和 Use-After-Free。启用方式是在编译和链接时传入 -fsanitize=address:
1 | // heap_overflow.c |
1 | clang -fsanitize=address -g -o heap_overflow heap_overflow.c |
ASan 会在第一个错误处终止程序,并输出详细的错误报告,包括错误类型、访问地址、分配/释放的调用栈。报告中的影子字节 (shadow byte) 信息直接反映了该地址在影子内存 (Shadow Memory) 中的状态编码。
ASan 内置了 LeakSanitizer (LSan) 的功能,但 LSan 也可以作为独立工具使用,下文单独展开。
LeakSanitizer (LSan)
LSan 检测堆内存泄漏——已分配但在程序退出时不再被任何指针可达的内存。LSan 有两种使用方式:一是作为 ASan 的附属功能自动启用,二是作为独立工具单独编译。
独立模式无需 ASan 的影子内存 (Shadow Memory) 开销,适用于只关心泄漏而不需要越界/UAF 检测的场景:
1 | // leak.c |
1 | # 独立模式(Linux、部分 BSDs):仅链接 LSan 运行时,不引入 ASan 开销 |
macOS 上 LSan 仍是 experimental,且有已知误报:上游 LLVM 文档至今把 AddressSanitizer 的 “Memory leaks” 能力 整体标记为
(experimental),且detect_leaks在 Apple 平台默认关闭——compiler-rt/lib/sanitizer_common/sanitizer_flags.inc中的定义即COMMON_FLAG(bool, detect_leaks, !SANITIZER_APPLE, ...),这就是为什么哪怕用 Homebrew 的上游 Clang,也仍要显式ASAN_OPTIONS=detect_leaks=1。此外,macOS arm64 上长期存在libobjc.A.dylib在 dyld 初始化阶段触发的系统库 false positive(issue llvm/llvm-project#115992,2024-11 报告,跨多个 macOS 版本复现),直到 2026-04-09 才由 PR #117478 通过在内置kStdSuppressions中追加*_fetchInitializingClassList*与*dyld4::RuntimeState::_instantiateTLVs*两条规则修复——该修复需 LLVM 21+ 才会进入正式 release,当前 LLVM 20.x 仍受影响。遇到此类系统库报告时,应通过LSAN_OPTIONS=suppressions=lsan.supp自行 suppress,而非误判为应用代码泄漏。
程序退出时 LSan 输出如下格式的报告:
1 | ERROR: LeakSanitizer: detected memory leaks |
LSan 的检测发生在 atexit 阶段:它遍历所有全局变量、栈帧、寄存器中的指针值,标记从这些根节点可达的所有堆分配为“可达”,剩余未标记的分配即为泄漏。这本质上是一次保守式 GC 标记 (mark) 过程——任何看起来像指针的值都被视为潜在引用,因此 LSan 的误报率极低,但并非绝对为零:在极端场景下(如指针存储于未被扫描的内存映射区域、或跨语言运行时使用了 LSan 无法感知的内存管理策略),可能出现少量误报。更常见的情况是漏报——指针被编码、压缩或存储在非标准位置时,LSan 无法将其识别为引用,导致仍被引用的内存被误判为泄漏。
当与 ASan 组合使用时,LSan 默认启用,无需额外标志。在独立模式下通过 -fsanitize=leak 启用。两种模式的关键差异:ASan + LSan 模式下 ASan 的隔离队列 (quarantine) 会延迟内存归还,可能影响泄漏判定的准确性(隔离队列中的内存虽已 free 但尚未归还分配器);独立 LSan 模式没有这一干扰。
LSan 可以通过 suppression 文件忽略已知的泄漏:
1 | LSAN_OPTIONS=suppressions=lsan.supp ./leak |
1 | # lsan.supp |
这在逐步修复大型代码库泄漏时非常实用——先 suppress 已知泄漏,防止新增泄漏被淹没。
macOS leaks 命令
leaks 是 macOS 系统自带的命令行工具,与 LSan 共享相同的设计思想——保守式 GC 扫描——但实现路径完全不同:它不需要在被检测程序中预先链接任何运行时,而是作为独立进程通过 Mach VM API 跨进程扫描目标的地址空间。相比之下,LSan 的实现并非“编译期插桩”——-fsanitize=leak 主要做的事是把 libclang_rt.lsan 链接进目标二进制,由它在运行时拦截 malloc/free 并在 atexit 阶段触发标记-清除 (mark-sweep);scanner 与目标程序处于同一地址空间。这种“外部附加 (attach)”的实现使得 leaks 可以在不重新编译、不链接任何额外库的前提下检测目标——典型场景是自己开发或自己启动的进程的 Release 构建、以及不便重新链接的闭源依赖;对受保护的系统进程或带限制性 entitlements 的目标,是否能附加取决于一组 macOS 访问控制规则,下文会单独说明。
最常见的两种用法:
1 | # 1. 对运行中进程做一次性泄漏快照(按 PID 或进程名) |
要让报告中带有完整的分配调用栈,需要启用 malloc 栈日志。--atExit 会自动开启该机制;手动附加运行中进程时则需提前设置环境变量:
1 | MallocStackLogging=1 ./my_program & |
leaks 的报告格式默认采用树形结构:顶层节点用 ROOT LEAK: 标签标注(即根集不可达的直接泄漏),其下缩进展示由该根泄漏间接引用、级联不可达的子分配(在 --list 经典模式下则会被平铺为独立条目)。每个泄漏条目包含字节数、分配地址和调用栈。底层算法与 LSan 一致——从寄存器、栈、全局段提取根集,对堆做保守标记-清除 (mark-sweep),未被标记的活跃分配即为泄漏。
但 leaks 并非“想附加到哪个进程就附加”——它依赖 task_for_pid 获取目标进程的 task port,而该调用受 macOS 系统级访问控制约束:
- 进程所有权:默认只能附加到同一用户启动的进程;附加到其他用户或更高权限的目标通常需要
sudo - SIP 与受保护进程:开启 SIP 时,Apple 签名的系统二进制(位于
/System/、/usr/libexec/等受保护路径)和带有 hardened runtime + 限制性 entitlements 的应用(典型如 Safari、Mail)即便以root身份也无法被附加 - 代码签名 entitlement:
leaks自身需要com.apple.security.cs.debugger等等价 entitlement 才能调试受签名/notarized 的目标;如果你重新签名了leaks二进制,需要补上对应 entitlement - Apple Silicon / arm64e:部分受保护进程额外通过 PAC 与 page protection 限制
mach_vm_read,在非特权环境下可能直接拒绝读取
因此 leaks 最可靠的场景是检测自己开发或自己启动的进程;对系统进程或 App Store 闭源应用,应当先确认目标可被调试(例如本地构建并禁用 hardened runtime、或在禁用 SIP 的开发机上排查),不要预设它们一定能被外部扫描到。
在权限允许的前提下,leaks 与 LSan 的关键差异:
- scanner 跑在哪:
leaks是独立进程,通过task_for_pid+mach_vm_read跨进程读取目标内存;LSan 是被链接进目标进程的运行时,直接读自身地址空间 - 是否改动二进制:
leaks完全不改动目标——适合排查无法重新编译的 Release 构建或闭源依赖(系统进程或 hardened runtime 应用需满足上述权限边界);LSan 必须重新链接(或通过LD_PRELOAD注入运行时) - 触发时机:
leaks可以在运行时任意时刻做快照,也可用--atExit在退出时扫描;LSan 只在atexit阶段扫描一次 - 平台绑定:仅在 macOS/iOS 可用;Xcode Instruments 中的 Leaks 模板就是基于
leaks实现的,提供图形化时间线和分配火焰图
对 macOS 开发者而言,由于 Apple Clang 既不支持 -fsanitize=leak、其 ASan 运行时也不支持 detect_leaks,leaks 命令往往是最便捷的本机泄漏检测方案。如果需要 LSan 等价体验(链接进程内运行时 + 分配器拦截 + suppression 机制 + CI 友好的非零退出码),仍需安装 LLVM 官方工具链。
MemorySanitizer (MSan)
MSan 检测对未初始化内存的读取。这类错误不会导致崩溃,但会引入不确定行为,是极难排查的隐蔽 Bug:
1 | // uninit.c |
1 | clang -fsanitize=memory -g -o uninit uninit.c |
MSan 要求被检测程序及其所有依赖库均使用 -fsanitize=memory 编译。如果链接了未插桩的库,MSan 会产生大量误报——这是实际使用中最常见的障碍。MSan 目前支持 Linux、NetBSD 和 FreeBSD(仅 Clang/LLVM,GCC 不提供 MSan 实现)。
ThreadSanitizer (TSan)
TSan 检测数据竞争(data race),即两个线程并发访问同一内存位置且至少一个是写操作,且没有通过同步原语建立先行发生 (happens-before) 关系。此外,TSan 还具备死锁检测(deadlock detection)和锁顺序反转(lock-order-inversion)检测能力——当程序中多个锁的获取顺序不一致时,TSan 会报告潜在的死锁风险:
1 | // race.c |
1 | clang -fsanitize=thread -g -o race race.c -lpthread |
TSan 基于先行发生 (happens-before) 语义而非简单的锁检测。它能正确处理 atomic 操作、mutex、condition_variable、std::call_once 等同步原语,只有在确认不存在先行发生关系时才报告竞争。
需要注意的关键约束:ASan、MSan、TSan 三者互斥,不能在同一次编译中同时启用。这是因为它们各自使用不同的影子内存 (Shadow Memory) 布局和运行时库,内存地址空间上存在冲突。UBSan 不受此约束,可以与任何一个 Sanitizer 组合使用。
HWAddressSanitizer
(HWASan) 是 ASan 的硬件辅助版本,其成熟部署路径基于 AArch64 的高位字节忽略 (Top-Byte Ignore, TBI) 特性——将标签嵌入指针高字节,大幅降低内存开销。x86 平台上 Intel 线性地址掩码 (Linear Address Masking, LAM) 和 AMD 高位地址忽略 (Upper Address Ignore, UAI) 提供了类似的高位忽略能力,但截至目前仍处于早期实验阶段,硬件和内核支持尚未普及,不应视为与 AArch64 TBI 同等成熟的部署基础:
1 | clang -fsanitize=hwaddress -g -o target target.c |
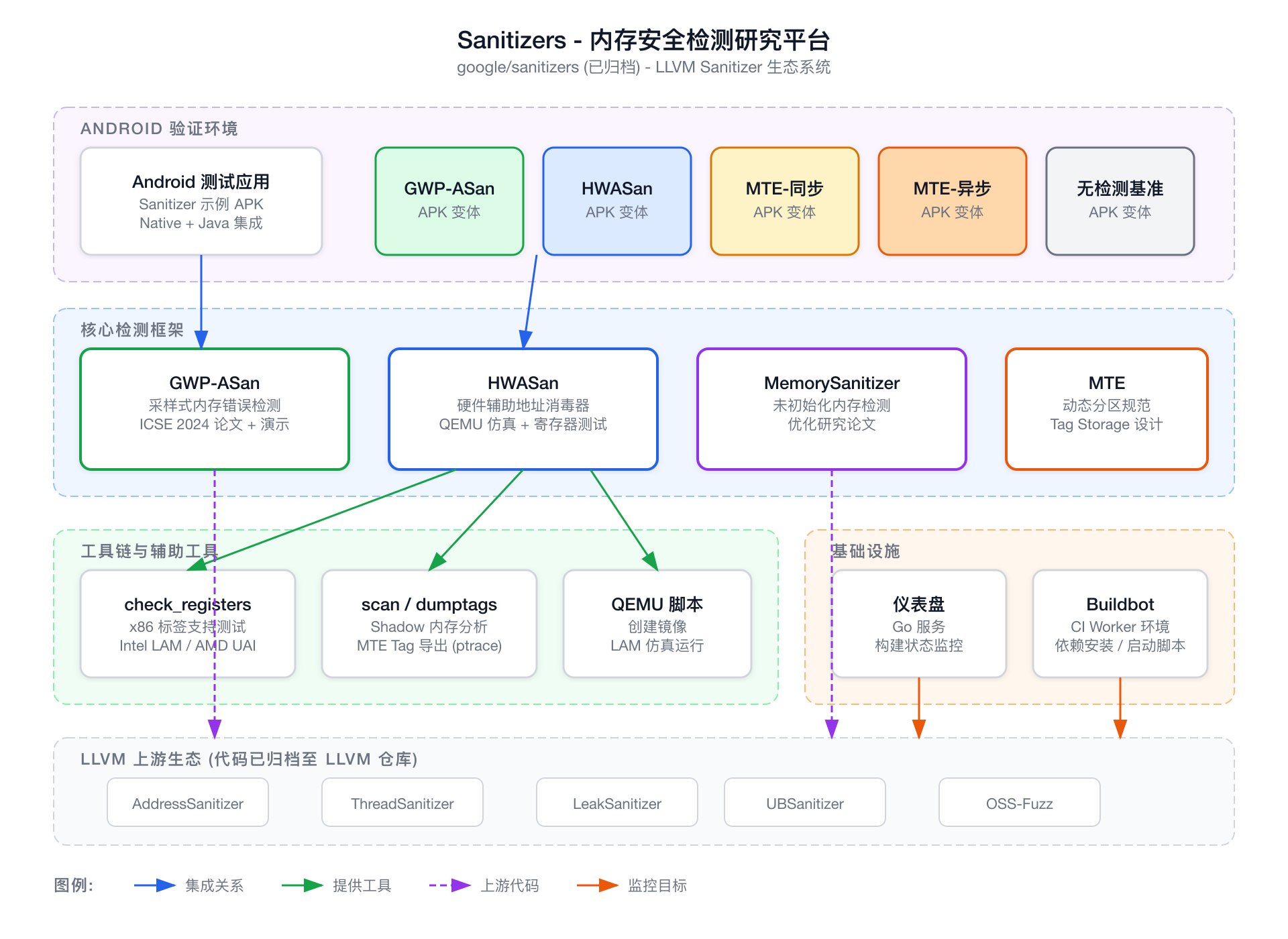
在 Android 系统上,HWASan 已深度集成。google/sanitizers 仓库中的 Android 测试应用通过 build flavor 和 manifest placeholder 来配置不同的检测模式:
1 | <!-- AndroidManifest.xml 中使用 placeholder --> |
1 | // build.gradle 中通过 productFlavors 配置具体值 |
HWASan 通过 CMake 参数 -DHWASAN=1 启用 NDK 层面的编译插桩;MTE 和 GWP-ASan 则通过 manifest 属性在运行时启用,无需重新编译 native 代码。
HWASan 的影子内存 (Shadow Memory) 映射比为 1:16(每 16 字节应用内存对应 1 字节影子内存),相比 ASan 的 1:8 映射减少了近一半的内存开销。但 HWASan 的标签仅有 8 bit(256 个可能值),存在约 1/256 的概率漏检——标签碰撞导致旧指针恰好匹配新分配的标签。
GWP-ASan
GWP-ASan 采用完全不同的策略:它不对所有分配插桩,而是以极低概率对堆分配进行采样,将被采样的分配放置在由 guard page 保护的专用内存区域中。越界访问触发 guard page 的页面保护异常,Use-After-Free 通过延迟取消映射检测。
1 | # Android 应用通过 manifest 启用 |
GWP-ASan 的核心价值在于其生产环境可用性——性能开销不到 1%,可以在海量用户设备上长期运行。单个设备的检测概率很低,但覆盖数十亿设备时,统计上仍能高效发现内存错误。Google 在 Android 11 中默认为系统进程启用了 GWP-ASan。
UndefinedBehaviorSanitizer (UBSan)
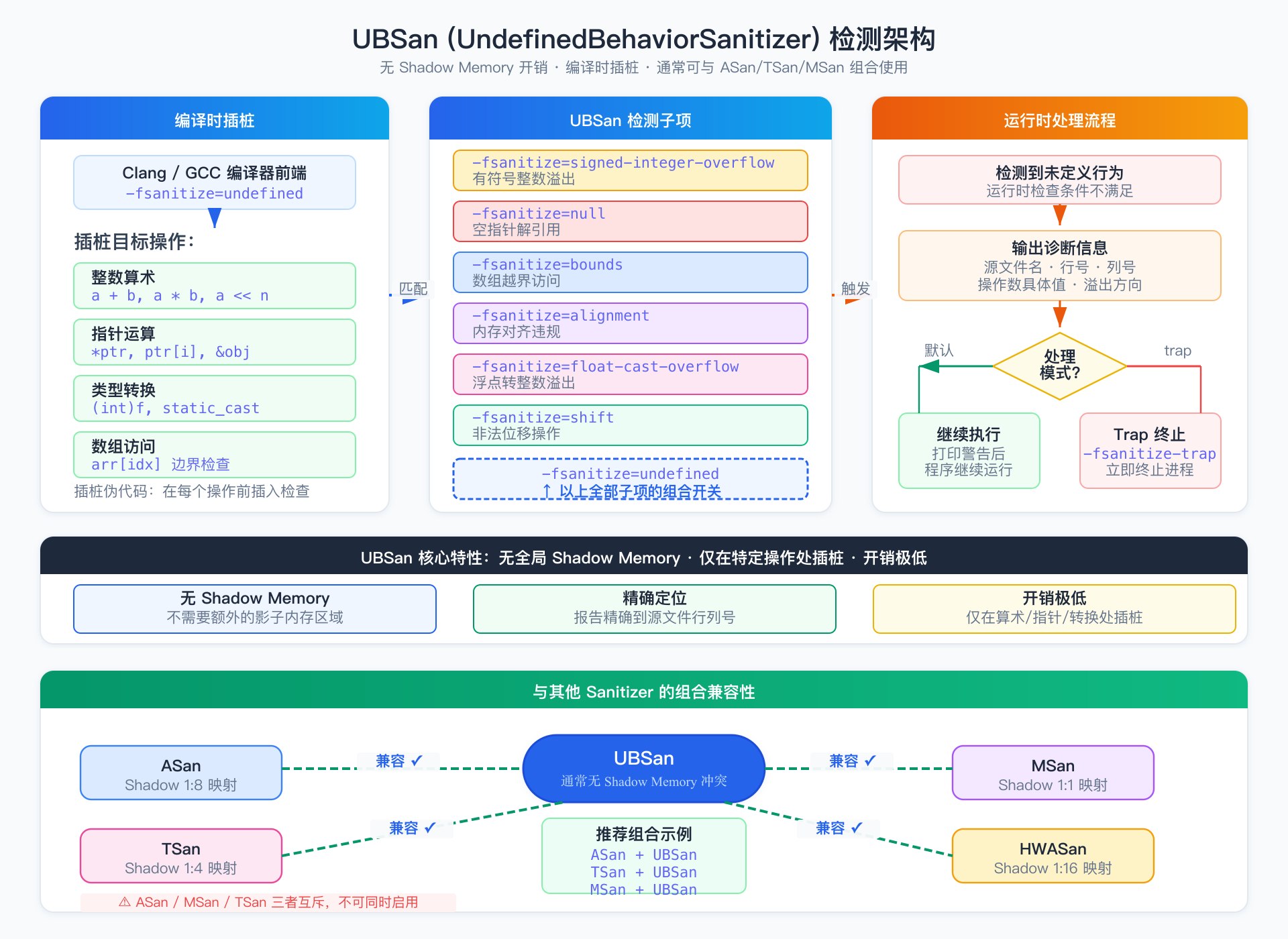
UBSan 检测 C/C++ 标准中定义的未定义行为(Undefined Behavior),这些行为在不同编译器、优化级别、目标架构下可能产生完全不同的结果。常见的检测项包括:有符号整数溢出、空指针解引用、除零、数组越界(通过 -fsanitize=bounds)、非法的类型转换(-fsanitize=undefined 涵盖的子项)等。
1 | // ubsan_example.c |
1 | clang -fsanitize=undefined -g -o ubsan_example ubsan_example.c |
UBSan 的一个独特优势是它通常可以与 ASan、TSan 等其他 Sanitizer 同时启用,不存在影子内存 (shadow memory) 冲突(具体兼容性因工具链版本和子项组合而异):
1 | # ASan + UBSan 组合使用 |
UBSan 的运行时开销通常很低(取决于启用的检测子项),因为大部分检查只在特定操作(如整数算术、指针运算、类型转换)时插入,不需要全局影子内存。部分子项(如 -fsanitize=bounds)的开销可以忽略不计。UBSan 同时支持 Clang 和 GCC,跨平台可用性好(Linux、macOS、Windows 均可使用)。
行为细节与常见误区
误区一:ASan 能检测所有内存错误。 ASan 无法检测未初始化读取(需要 MSan)和数据竞争(需要 TSan)。ASan 的越界检测依赖红区 (redzone),如果越界跨度恰好跳过红区落在另一个合法分配上,也会漏检。
误区二:TSan 报告的竞争一定会导致 Bug。 TSan 报告的是违反内存模型的行为,即使当前硬件上运行正确,在更弱的内存序架构(如 ARM)或编译器优化后可能产生实际问题。TSan 报告的竞争应当全部修复,而非通过实际运行结果判断是否“真的有问题”。
误区三:HWASan 可以替代 ASan。 HWASan 的检测粒度是 16 字节(shadow 粒度),小于 16 字节的越界访问可能无法检测。ASan 的红区 (redzone) 粒度更细,可以检测到单字节越界。在开发环境中,ASan 仍然是更精确的选择。
误区四:GWP-ASan 的“低概率”意味着无用。 GWP-ASan 设计目标不是单机检测,而是大规模统计检测。当部署到百万级设备时,即使单设备采样率为 1/1000,每天触发的检测量仍然可观。它的价值体现在分母足够大时。
误区五:LSan 报告泄漏就意味着有 Bug。 某些场景下程序故意不释放内存——例如进程退出前的全局缓存、单例对象。这些是“有意为之的泄漏”而非 Bug。LSan 提供 suppression 机制和 __lsan_disable() / __lsan_enable() API 来标记这些例外。但需要警惕的是,用 suppression 掩盖真实泄漏:每条 suppression 规则都应当有明确的注释说明为什么该泄漏是可接受的。
误区六:Sanitizer 引入的性能开销是固定的。 实际开销与程序行为高度相关。内存密集型程序(频繁 malloc/free、大量指针运算)的 ASan 开销远高于计算密集型程序。TSan 对锁争用激烈的场景开销可达 15x,但对无锁代码可能只有 5x。
内部原理

ASan:影子内存与红区
ASan 的核心机制是影子内存 (Shadow Memory)——一块与应用内存建立固定映射关系的元数据区域。每 8 字节应用内存对应 1 字节影子内存 (shadow),编码方式如下:
0x00:8 字节全部可访问0x01-0x07:前 N 字节可访问,其余不可访问0xfa:堆左红区(heap left redzone)0xfd:已释放的堆内存(隔离队列中)0xf1-0xf4:栈左/中/右/部分红区 (redzone)0xf5:函数返回后使用栈内存(stack-use-after-return)
地址到影子内存的映射公式是确定性的:
1 | shadow_addr = (app_addr >> 3) + shadow_offset |
编译器在每个内存访问指令前插入检查代码。以 8 字节对齐读取为例,伪代码如下:
1 | // 编译器在 *addr 前插入的检查 |
对于堆分配,ASan 替换了 malloc/free 实现。malloc 在分配区域两侧插入红区 (redzone)(默认 16 字节,可配置),并在影子内存 (shadow memory) 中将红区标记为不可访问。free 不立即归还内存,而是将其放入隔离队列 (quarantine),隔离队列中的内存影子状态被标记为 0xfd,任何访问都会触发报错。隔离队列满后,最早释放的内存才被真正归还。
这个设计决定了 ASan 的两个核心代价:影子内存带来约 1/8 额外内存占用(加上红区和隔离队列,实际约 2-3 倍),插桩检查带来约 2 倍 CPU 开销。
LSan:退出时保守 GC 扫描
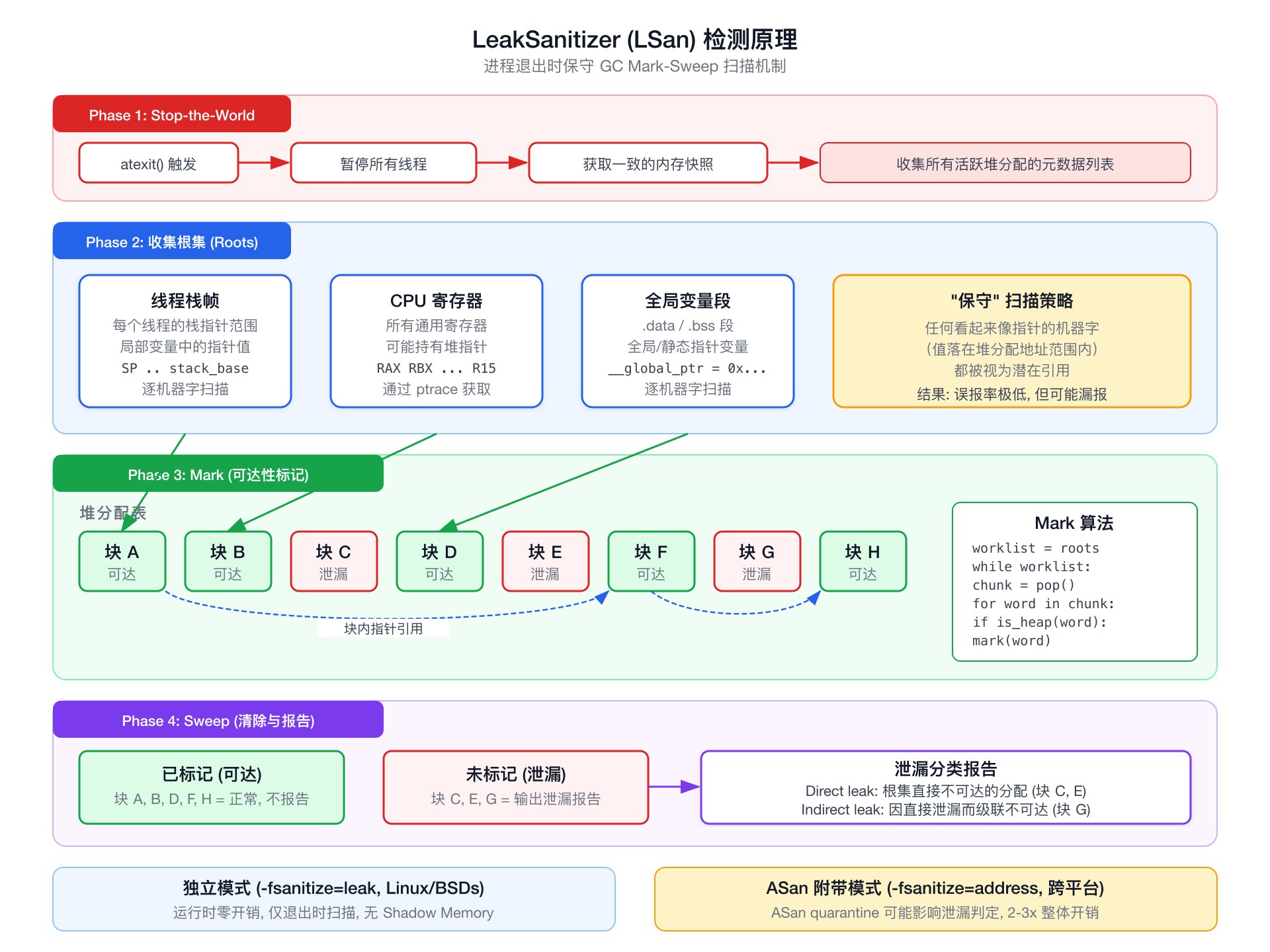
LSan 的检测算法在程序退出时执行一次,核心是保守式垃圾回收(conservative GC)的标记-清除 (mark-sweep) 过程:
- Stop-the-world:暂停所有线程,获取一致的内存快照。
- 收集根集:扫描所有线程的栈帧、寄存器、全局变量段(
.data/.bss),提取所有看起来像指针的值——即落在堆分配地址范围内的机器字。这是“保守”的含义:整数值恰好与某个堆地址相同也会被视为引用。 - Mark 阶段:从根集出发,递归标记所有可达的堆分配块。可达块内部的每个机器字同样作为潜在指针参与扫描。
- Sweep 阶段:未被标记的堆分配即为泄漏。LSan 按“直接泄漏”(根集直接不可达)和“间接泄漏”(因直接泄漏块不可达而级联不可达)分类报告。
1 | // 保守 GC 的伪代码 |
独立 LSan 模式的开销极低——运行时不做任何额外工作,仅在退出时执行一次标记-清除 (mark-sweep)。扫描时间与进程的内存映射数量和活跃堆分配数量成正比,大多数程序在毫秒级完成。
HWASan:Top-Byte Ignore 与硬件标签
HWASan 利用了一个硬件特性:AArch64 处理器可以配置为忽略虚拟地址的高字节(bit 56-63)。这意味着指针 0x0a001234_00005678 和 0x00001234_00005678 指向相同的物理内存,但高字节 0x0a 可以被软件用作元数据——这就是指针标签。
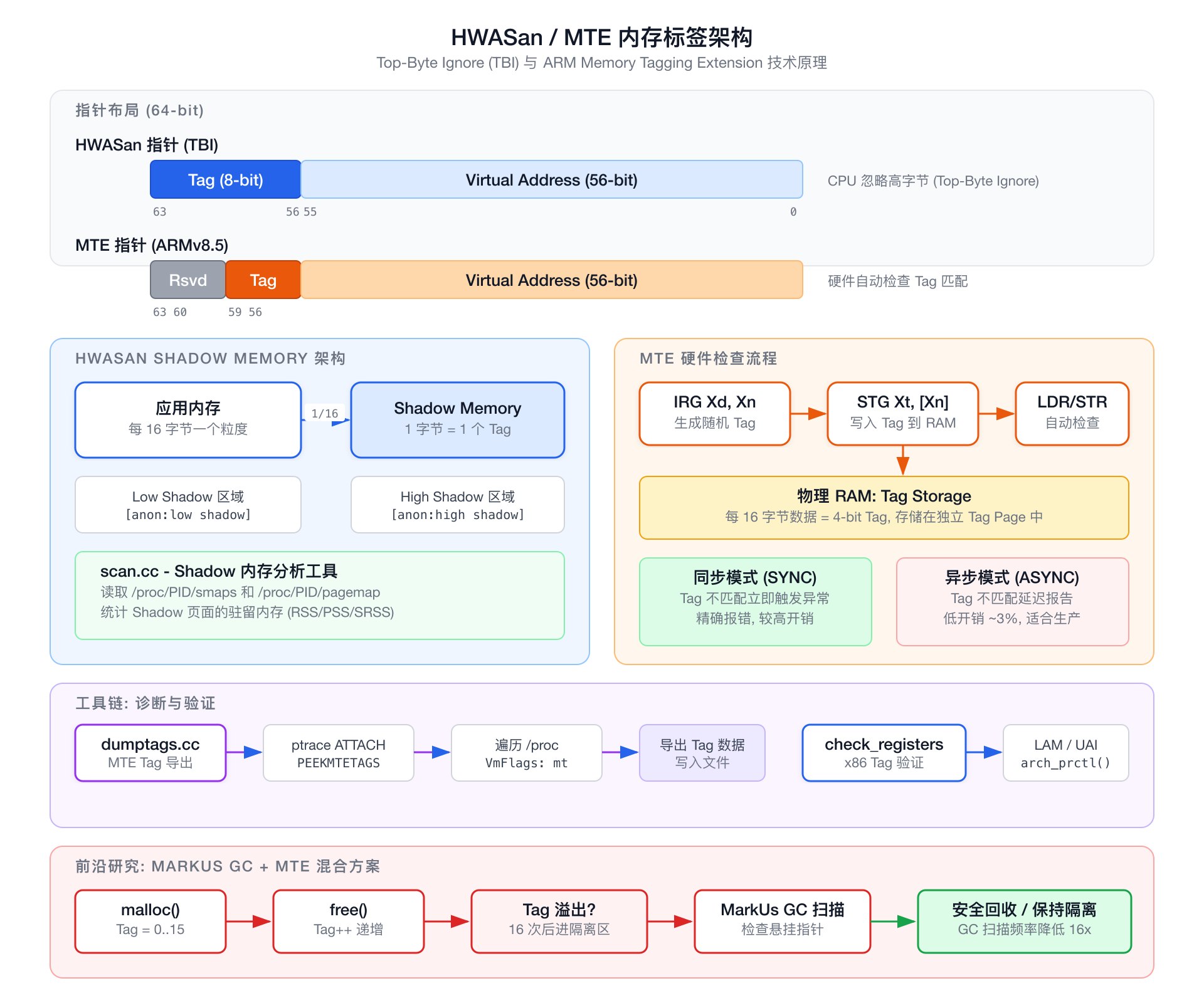
HWASan 的工作流程:
- 分配时:为每个堆分配生成一个随机的 8-bit 标签 T,将 T 写入指针高字节,同时将 T 写入该分配对应的所有影子内存 (shadow) 字节。
- 访问时:编译器插入的检查代码提取指针高字节标签 Tp,查询目标地址的影子内存标签 Ts,比较
Tp == Ts。不匹配则报错。 - 释放时:为该内存区域生成新的随机标签并写入影子内存。旧指针携带的标签不再匹配,后续 Use-After-Free 访问被捕获。
影子内存映射比为 1:16(每 16 字节应用内存 1 字节影子内存),这也意味着检测粒度为 16 字节——相邻分配之间如果没有 16 字节对齐边界,小范围越界可能漏检。
在 x86 平台上,Intel LAM (Linear Address Masking) 和 AMD UAI (Upper Address Ignore) 提供了类似的高位忽略能力,但这些特性仍处于逐步落地阶段——需要较新的 CPU 微架构(如 Intel Meteor Lake 及之后)和内核支持(Linux 6.2+),目前远未达到 AArch64 TBI 的生态成熟度。google/sanitizers 仓库中的 check_registers 工具正是用于验证这些 x86 硬件特性在不同寄存器和指令组合下的行为——数据传送指令(mov、movaps)应当正确忽略高位标签,而控制流指令(call、jmp、ret)应当拒绝带标签的指针,防止标签被误用于控制流劫持。
MTE:硬件原生标签检测
ARM 内存标签扩展 (Memory Tagging Extension, MTE, ARMv8.5-A) 将标签检测从软件插桩推进到硬件原生支持。MTE 使用指针 bit 56-59 存储 4-bit 标签(16 个可能值),标签存储在物理 RAM 中独立的 Tag Storage 区域(非 ECC 存储),每 16 字节数据对应 4-bit 标签。
MTE 提供了专用指令:
- IRG (Insert Random Tag):生成随机标签并写入指针
- STG (Store Tag):将指针标签写入内存对应的 Tag Storage
- LDG (Load Tag):从 Tag Storage 加载标签
关键区别在于:标签检查由 CPU 在每次 LDR/STR 指令执行时自动完成,无需编译器插入额外检查代码。这消除了 ASan/HWASan 的插桩开销。
MTE 支持两种运行模式:
- 同步模式 (SYNC):标签不匹配时 CPU 立即触发同步异常,提供精确的错误位置。适用于开发测试,开销约 5-10%。
- 异步模式 (ASYNC):标签不匹配被记录到系统寄存器
TFSR_EL1,不立即中断执行,在下次内核入口(如系统调用、中断)时才检查并报告。适用于生产环境,公开资料中常见的开销量级为几个百分点,具体取决于硬件实现、内核版本和工作负载特征。
4-bit 标签意味着约 1/16 的碰撞概率。对于安全加固场景,这个概率已经足以大幅提升漏洞利用的难度——攻击者需要在每次尝试中以 15/16 的概率触发异常。
MTE Dynamic Tag Storage:灵活的物理内存管理
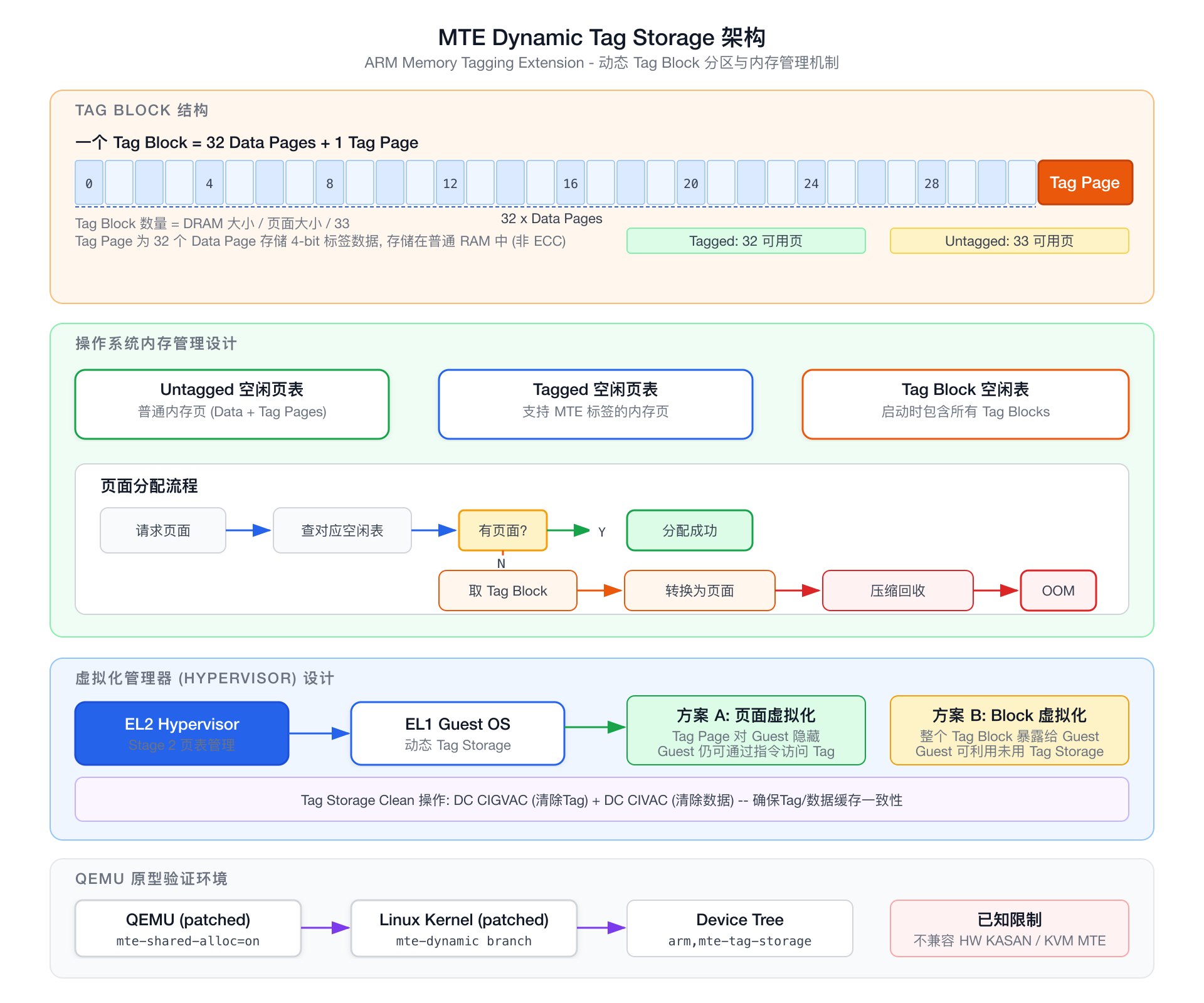
MTE 的 Tag Storage 占用物理 RAM(每 16 字节数据 4-bit 标签,即 32 个数据页需要 1 个标签页)。google/sanitizers 仓库中的 MTE Dynamic Carveout 规范提出了一种灵活的物理内存管理方案,允许操作系统在运行时动态决定一个 Tag Block(32 Data Pages + 1 Tag Page)是用于存储带标签的数据还是普通数据。
操作系统维护三个空闲链表:
- Untagged 空闲页表:普通内存页
- Tagged 空闲页表:支持 MTE 标签的内存页
- Tag Block 空闲表:启动时包含所有 Tag Block
页面分配流程:首先查对应类型的空闲页表;如果为空,从 Tag Block 空闲表取出一个 Block 并转换(tagged 模式产出 32 页,untagged 模式产出 33 页);如果 Tag Block 也耗尽,则从另一类型的空闲页表中压缩回收。
这个设计的关键价值在于:不使用 MTE 的进程无需为 Tag Storage 付出任何内存代价——Tag Page 可以作为普通数据页使用。只有当系统中确实有进程启用 MTE 时,Tag Page 才被预留。规范还定义了 Tag Storage Clean 操作(DC CIGVAC + DC CIVAC)确保在模式切换时标签缓存和数据缓存的一致性。
MarkUs GC + MTE:混合方案的潜力
google/sanitizers 仓库中对 MarkUs GC 论文的分析揭示了一个有趣的混合策略:将 MTE 标签与 GC 式 quarantine 结合,可以将 GC 扫描频率降低 16 倍。
原理:每个堆分配的初始标签为 0,每次 free 时标签递增。在标签溢出(第 16 次释放同一区域)之前,MTE 硬件自动阻止 Use-After-Free——旧指针的标签不匹配当前标签。只有当标签耗尽(回绕到 0)时,才需要将该内存放入隔离队列 (quarantine) 并启动 GC 扫描检查是否仍有悬挂指针。
这意味着 MarkUs 的 GC 扫描成本被摊薄了 16 倍,使得原本在高分配速率场景下代价高昂的 GC 方案变得可行。
性能与特性分析
各 Sanitizer 的性能开销差异巨大,根本原因在于检测机制的不同。以下数字为社区广泛引用的典型范围(主要来源于 LLVM 官方文档、Google 发表的原始论文及 Android 安全团队的公开报告),实际开销因工作负载特征、目标架构、编译器版本而异,应以自身项目的基准测试为准:
ASan 的开销主要来自两部分:每次内存访问前的影子内存检查(CPU 开销约 2x)和影子内存 (shadow memory) + 红区 (redzone) + 隔离队列 (quarantine) 的额外内存(RAM 开销约 2-3x)。影子内存检查是一次内存读取加一次条件判断,在现代 CPU 上通常命中 L1 缓存,开销相对可控。
LSan(独立模式) 在运行阶段几乎零开销——它替换了 malloc/free 以追踪分配元数据,但不插入任何内存访问检查。代价集中在进程退出时的单次 mark-sweep 扫描,耗时与堆分配数量和内存映射规模成正比。对于分配数百万对象的大型进程,退出时的扫描可能需要数秒,但对程序运行期性能没有影响。与 ASan 组合使用时,LSan 的退出扫描开销被 ASan 本身的 2-3x 开销掩盖。
MSan 的开销略高于 ASan(CPU 约 3x),因为它需要跟踪每个字节的初始化状态,并在值传播时传递 shadow 状态——一次加法 c = a + b 不仅要计算 c 的值,还要计算 c 的 shadow(即 c 是否被初始化取决于 a 和 b 的 shadow 状态)。
TSan 的开销最高(CPU 5-15x,RAM 5-10x),因为它需要为每个内存访问维护向量时钟 (vector clock) 状态来追踪先行发生 (happens-before) 关系。每个 8 字节内存对应的影子内存 (shadow) 区域需要存储最近多个线程的访问时间戳,影子内存映射比为 1:4(远高于 ASan 的 1:8)。
HWASan 在 AArch64 上的 CPU开销约 15%,RAM 开销约 15%。相比 ASan 大幅改善的原因是影子内存映射比为 1:16 且无需红区 (redzone),但仍需要编译器插入标签比较指令。
MTE (ASYNC) 的 CPU 开销通常在几个百分点量级,是所有方案中最低的。硬件自动完成标签检查,无需插桩指令。Tag Storage 的 RAM 开销约为 1/32 的物理内存用于标签存储。具体数值取决于硬件实现(不同 SoC 的 MTE 实现效率不同)、内核版本和负载特征,应以目标平台的实测为准。
GWP-ASan 的开销不到 1%——绝大多数分配走正常路径,只有被采样的极少数分配有额外开销。代价是检测概率极低,无法保证单次运行一定能发现错误。
技术方案对比
从检测维度看,这些工具覆盖不同的缺陷类型,互为补充而非替代:
ASan 和 HWASan 针对空间安全(越界)和时间安全(UAF),区别在于实现机制:ASan 纯软件、更精确(字节粒度)、开销更高;HWASan 借助硬件 TBI、粒度较粗(16 字节)、开销更低。MTE 在 HWASan 的方向上更进一步,将检测完全交给硬件,代价是标签空间从 8-bit 缩减到 4-bit,碰撞概率从 1/256 上升到 1/16。
从部署阶段看,形成了清晰的分层策略:
- 开发/测试环境:ASan + UBSan / MSan + UBSan / TSan(分别编译运行),追求最大检测精度
- CI/预发布:HWASan,在可接受的开销下持续检测
- 金丝雀/灰度:HWASan 或 MTE SYNC,覆盖更接近真实的负载
- 全量生产:GWP-ASan 或 MTE ASYNC,开销足够低以长期运行
与 Rust/Go 等内存安全语言相比,Sanitizer 的定位是为无法迁移的 C/C++ 代码库提供防御。Rust 的所有权系统在编译时消除大多数内存安全问题,但无法应用于现存的数十亿行 C/C++ 代码。Sanitizer 是在不改变语言的前提下最有效的动态检测手段。
与 Valgrind 相比,ASan 的优势在于性能:Valgrind 基于动态二进制插桩(dynamic binary instrumentation),CPU 开销通常在 10-50x,而 ASan 通过编译时插桩仅有约 2x。Valgrind 的优势是无需重新编译,但在大规模持续集成中,编译时插桩的方案更为实用。
实践建议
适合启用 ASan 的场景:所有 C/C++ 项目的 CI 流水线。将 ASan 编译作为 CI 的标准步骤,与普通编译并行运行。ASan 编译的测试套件可以同时覆盖功能正确性和内存安全性。ASan 默认包含 LSan,一次编译同时检测越界、UAF 和泄漏。
适合独立使用 LSan 的场景:对性能敏感的集成测试或端到端测试。独立 LSan(-fsanitize=leak)不引入运行时开销,适合在测试周期较长、无法承受 ASan 2x 开销的场景下仅检测泄漏。独立模式在 Linux 上支持最完善,部分 BSDs 也可用;macOS 上 Apple Clang 既不支持 -fsanitize=leak,其 ASan 运行时也不支持 detect_leaks 选项,需安装 LLVM 官方工具链(如 brew install llvm)并使用其 clang 进行编译,或直接使用系统自带的 leaks 命令(详见上文「macOS leaks 命令」一节)作为本机替代。也适用于已经通过 ASan 排除了越界/UAF 后,需要在接近 Release 的编译配置下专门追踪泄漏的阶段。
适合启用 TSan 的场景:涉及多线程的代码库,尤其是使用了无锁数据结构或细粒度锁的模块。TSan 的误报率在正确插桩的情况下极低,报告的每一个竞争都值得认真对待。
不适合使用 MSan 的场景:依赖大量第三方闭源库的项目。MSan 要求所有链接的代码均已插桩,未插桩的函数返回值会被误判为未初始化。如果无法重新编译所有依赖,考虑使用 Valgrind 的 memcheck 替代。
生产环境低开销检测方案:对于 Android 应用和服务端长运行进程,GWP-ASan 是目前最广泛部署的低开销生产检测方案之一。如果目标设备支持 ARMv8.5-A,MTE ASYNC 模式是另一重要选择——检测概率从采样(极低概率)提升到确定性(仅有 1/16 碰撞率),开销仍然可控。两者的选择取决于目标平台的硬件支持和部署条件。
常见错误用法:
- 在 Release 编译中启用 ASan 并期望“顺便检测”——ASan 禁用了部分编译器优化,且增加的内存开销可能改变程序的时序行为,导致并发 Bug 被掩盖或触发。Sanitizer 应当有独立的 CI 构建配置。
- 忽略 ASan 报告中的
alloc-dealloc-mismatch——new[]配delete(而非delete[])在某些平台上“恰好能工作”,但属于未定义行为,在其他平台或优化级别下会崩溃。 - 将 ASan 和 TSan 放在同一个编译目标中——二者使用不同的影子内存布局,同时启用会在链接阶段或运行时崩溃。
总结
Sanitizer 技术的本质是用可控的运行时代价换取内存安全和行为正确性的动态验证。从 ASan 的影子内存 (shadow memory) 编译插桩,到 LSan 的退出时保守式 GC 扫描,到 UBSan 对未定义行为的细粒度检测,到 HWASan 利用指针高位存储标签,再到 MTE 将检测逻辑下沉到 CPU 微架构,每一步演进都在降低检测开销的同时保持有效的错误捕获率。没有单一工具能覆盖所有缺陷类型和部署阶段——正确的策略是在开发、测试、生产环节分别部署适合的工具,构建多层防御。对于仍在使用 C/C++ 的工程团队,在 CI 中启用 ASan(含 LSan)+ UBSan 和 TSan 是投入产出比最高的安全实践,没有之一。

