你写了一个函数,想知道它到底多快。最直觉的做法是:循环跑一万次,除以一万,得到”平均耗时”。但问题是——你测到的不只是函数本身,还有循环开销、计时器精度、CPU 缓存状态、系统调度噪声,甚至输入构造和对象析构的成本。
Criterion.rs 就是为了解决这个问题而设计的 Rust 微基准测试库。它不只是帮你”计时”,而是帮你做一套完整的统计实验:
- 预热(warm-up)——先把被测函数跑一阵子,让 CPU 缓存和分支预测稳定下来
- 自适应采样——根据函数快慢自动决定每个样本跑多少次
- 计时隔离——通过不同的计时循环,让你选择把哪些开销排除在测量之外
- 统计分析——用 bootstrap(自助法重采样)和线性回归,从有噪声的样本里得出带置信区间的结论
- 基线对比——和上次运行比较,用假设检验判断性能是否真的变了
换句话说,它回答的问题不是”这次跑了多久”,而是**“在噪声下,我们能有多大把握说这个函数的典型耗时是多少、相对上次是否真的变了”**。
本文分析的源码固定在 criterion-rs/criterion.rs 仓库提交 60ab5fd,包版本为 0.8.2[1]。所有源码链接都指向该 commit。
术语速查表
后文会频繁使用以下术语。第一次阅读时可以跳过这张表,遇到不熟悉的名词再回来查。
| 简称/术语 | 全称 | 中文说明 |
|---|---|---|
| Criterion.rs | Criterion.rs | Rust 生态常用的统计驱动微基准测试库 |
| Microbenchmark | Microbenchmark | 微基准:测量一个很小函数、代码片段或单一操作的性能 |
| Harness | Benchmark Harness | 基准测试运行器;Criterion.rs 通过 harness = false 自建入口 |
| Warm-up | Warm-up Phase | 预热阶段:重复执行被测逻辑,让缓存、CPU、OS 状态稳定,并估计单次耗时 |
| Measurement | Measurement Phase | 测量阶段:按样本计划收集 (iters, elapsed) 数据 |
| Timing loop | Timing Loop | Bencher 提供的计时循环,如 iter、iter_batched、iter_custom |
| Sample | Sample | 样本;Criterion.rs 里一个样本通常包含多次迭代的总耗时 |
| Bootstrap | Bootstrap Resampling | 自助法重采样;用有限样本构造估计量分布和置信区间 |
| CI | Confidence Interval | 置信区间;Criterion.rs 默认置信水平为 0.95 |
| MAD | Median Absolute Deviation | 中位数绝对偏差;对离群点更稳健的离散程度估计 |
| IQR | Interquartile Range | 四分位距;Tukey 离群点分类使用的核心量 |
| OLS | Ordinary Least Squares | 普通最小二乘;Criterion.rs 用过原点直线 y = m * x 拟合斜率 |
| MET | Mean Execution Time | warm-up 得到的粗略单次执行时间,源码里变量名为 met |
| Baseline | Baseline Sample | 上一次保存的基线样本,用于对比当前运行 |
1. 从零运行一个 Criterion.rs 基准测试
1.1 前提条件
你需要一个可用的 Rust 工具链。如果还没有安装,执行:
1 | curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh |
安装完成后确认 cargo 可用:
1 | cargo --version |
1.2 搭建项目
新建一个 Rust 库项目:
1 | cargo init --lib fib-bench && cd fib-bench |
项目搭建完成后的目标结构如下(fib.rs 在下一步创建):
1 | fib-bench/ |
Criterion.rs 的 benchmark 不走 Rust 内置的 #[bench](那个需要 nightly),而是通过 harness = false 告诉 Cargo[4]:“这个 benchmark 有自己的 main() 入口,不要用默认的 libtest harness”。
1.3 添加依赖和 benchmark 入口
编辑 Cargo.toml,在末尾加上:
1 | [dev-dependencies] |
name = "fib"决定了后面运行时用--bench fib来指定它。如果你的文件叫benches/sorting.rs,这里就写name = "sorting"。
1.4 编写 benchmark 代码
创建 benches/fib.rs:
1 | // benches/fib.rs |
为什么压低参数? 这里的
sample_size(10)和nresamples(1000)是为了演示时快速完成。nresamples低于 Criterion.rs 的建议阈值,运行时会看到一行警告——这是正常的,不影响结果。实际项目中应使用默认值(sample size 100、warm-up 3s、measurement 5s、bootstrap resamples 100000),这些默认值在src/lib.rs:390-423初始化。
1.5 运行 benchmark
1 | cargo bench --bench fib -- --noplot |
-- 是分隔符——左边的参数给 cargo,右边的参数给 benchmark 可执行文件(也就是 Criterion.rs)。
1.6 理解输出
首次运行(没有历史基线)的输出:
1 | Benchmarking fib 20 ← 开始测 "fib 20" |
首次运行不会出现 change: 行,因为还没有历史基线可比较。
第二次运行(已有基线)会多出对比信息:
1 | fib 20 time: [10.824 µs 10.863 µs 10.897 µs] |
关键信息:Criterion.rs 不是给你一个数字说”跑了 10.863 微秒”就完了。它给的是一个区间加一个统计判定——“在 95% 的置信水平下,真实耗时大概落在 10.824~10.897 µs 之间;和上次比,没有统计显著的性能变化”。
2. 产物分析:Criterion.rs 到底保存了什么
运行完 benchmark 后,Criterion.rs 会在 target/criterion/ 下按测试名创建目录,保存原始数据和统计结果。这些文件是理解 Criterion.rs 做了什么的关键——CLI 输出只是冰山一角。
2.1 目录结构
首次运行后的目录结构:
1 | target/criterion/ |
第二次运行时,如果 base/ 已存在,Criterion.rs 会对比 new/ 和 base/ 的数据,并额外生成:
1 | └── change/ |
在默认的 Baseline::Save 模式下,每次运行结束后 new/ 的内容会自动复制到 base/,成为下一次运行的比较基准。如果设置为 Baseline::Discard,则不会保存基线。
2.2 sample.json——原始测量数据
这是最重要的文件,保存了 Criterion.rs 实际测量到的原始数据:
1 | { |
逐字段解释:
| 字段 | 类型 | 含义 |
|---|---|---|
sampling_mode | 字符串 | 采样策略。"Linear" 表示每个样本的迭代次数按等差递增(324, 648, 972…);"Flat" 则每个样本迭代次数相同 |
iters | 数组 | 每个样本的迭代次数。10 个样本,第 1 个跑了 324 次 fibonacci,第 2 个跑了 648 次……第 10 个跑了 3240 次 |
times | 数组 | 每个样本的总耗时(单位:纳秒)。第 1 个样本 324 次迭代总共花了 3,676,333 ns(约 3.7 ms) |
注意:times 不是单次迭代耗时,而是整个样本的总耗时。 Criterion.rs 在分析阶段通过 elapsed / iters 计算每次迭代的平均耗时 avg_times,见 src/analysis/mod.rs:124-129。
用第 1 个样本验算:3676333 / 324 ≈ 11,346 ns ≈ 11.3 µs——和 CLI 输出的 ~10.86 µs 量级一致(最终估计是所有样本的统计结果,而非单个样本)。
为什么第一个样本恰好是 324 次? 这不是随机数,而是 Criterion.rs 根据 warm-up 结果反推出来的。推导过程如下:
warm-up 阶段估计出单次迭代耗时 (Mean Execution Time)。对 fib 20,warm-up 得到的估计大约是:
Linear 模式下, 个样本的迭代次数是 ,总迭代次数为:
预期总耗时 ,需要控制在 measurement_time(本例 200 ms)以内。反解 :
所以迭代次数序列就是 。
这个公式的源码在 src/lib.rs:1427-1455。
为什么要递增迭代次数? 因为 (iters, times) 构成了一组 数据点,可以拟合一条过原点的直线 ,斜率就是单次迭代耗时的更稳健估计(Criterion.rs 把这个斜率称为 slope)。下面的散点图展示了 sample.json 里的实际数据——蓝色点是 10 个样本,红色线是回归直线,斜率约 10,863 ns(≈ 10.86 µs):
从图上可以直观看到:10 个样本点几乎完美排列在一条直线上。这说明 fibonacci(20) 的单次耗时非常稳定,线性回归的斜率(红色线的倾斜程度)就是单次迭代耗时的最佳估计。
如果简单用 elapsed / iters 计算每个样本的平均耗时,第 1 个样本(324 次迭代)算出 11,346 ns,第 10 个样本(3240 次迭代)算出 10,893 ns——差了 4%。这个差异可能来自计时器固定开销、缓存预热、CPU 频率变化等因素的混合影响;迭代次数越少,这些固定因素的占比越大。而回归斜率 10,863 ns 综合了所有样本,能更好地抵消这些干扰。
2.3 estimates.json——统计估计结果
在看这个文件之前,先理解三个统计概念——它们是 Criterion.rs 整套方法论的基础。
什么是点估计、置信区间和 bootstrap?
点估计(point estimate) 是对一个未知量的”最佳猜测”。比如你跑了 10 个样本,算出平均耗时是 10,870 ns——这就是均值的点估计。但问题是:如果你再跑 10 个样本,平均值可能变成 10,850 或 10,900。单个数字无法告诉你”这个估计有多靠谱”。
置信区间(confidence interval, CI) 解决的就是这个问题。一个 95% 的置信区间 的含义是:如果你用同样的方法反复做实验,95% 的情况下,算出的区间会包含真实值。区间越窄,估计越精确。
bootstrap(自助法重采样) 是 Criterion.rs 用来计算置信区间的方法。它的核心思路出奇简单:
既然你只有 10 个样本,那就从这 10 个样本里有放回地随机抽 10 个,算一次均值;重复这个过程 1000 次(或默认的 100,000 次),你就得到了 1000 个均值。把这 1000 个均值从小到大排序,取第 2.5% 和第 97.5% 位置的值,就是 95% 置信区间。
用 fib 20 的 10 个样本 avg_times 走一遍:
1 | 原始 avg_times(ns): |
标准误差(standard error) 是这 1000 个均值的标准差——它衡量”点估计本身有多大的随机波动”。标准误差越小,说明即使重新采样,点估计也不会变太多。
estimates.json 的内容
理解了上面三个概念,这个文件就很好读了。以下是真实产物(为可读性做了缩进):
1 | { |
每个估计量都包含三部分:
| 子字段 | 含义 | 用上面的 mean 举例 |
|---|---|---|
point_estimate | 最佳估计值(纳秒) | 10870.03 ns — 均值的最佳猜测 |
confidence_interval | 95% 置信区间 | ns — bootstrap 1000 次后排序取边界 |
standard_error | 估计值的波动性 | 24.36 ns — bootstrap 出的 1000 个均值的标准差 |
五个估计量分别是什么:
| 估计量 | 用一句话解释 | 什么时候看 |
|---|---|---|
mean | 10 个样本平均耗时的 bootstrap 估计 | 基本指标,但如果有离群点会被拉偏 |
median | 10 个样本中位数耗时的 bootstrap 估计 | 比 mean 更抗离群点——1 个异常值不影响中位数 |
median_abs_dev (MAD) | 每个样本和中位数的距离的中位数 | MAD 越大说明样本波动越大,benchmark 可能不稳定 |
slope(斜率) | 线性回归斜率的 bootstrap 估计(Linear 模式专属) | Criterion.rs 优先使用的估计,CLI 输出的就是它 |
std_dev(标准差) | 样本的离散程度 | 评估测量的整体波动性 |
slope(斜率)vs mean(均值):为什么 Criterion.rs 优先用斜率?
mean(均值)是把每个样本的elapsed / iters简单平均。slope(斜率)是用所有 10 个 点做线性回归得到的斜率。区别在于:斜率利用了”不同迭代次数下的表现”这个额外信息,能更好地消除计时器固定开销的影响。从 JSON 里也能看到slope的standard_error(标准误差,18.59)比mean的(24.36)更小,说明斜率估计更稳定。
CLI 输出和 JSON 的对应关系:
Linear模式下,CLI 输出的time:行取自slope(斜率)的[lower_bound(下界), point_estimate(点估计), upper_bound(上界)];Flat模式下没有斜率,time:行取自mean(均值)。而change:行始终反映的是均值(mean)的相对变化,不是斜率。上面例子是Linear模式,所以time: [10.824 µs 10.863 µs 10.897 µs]就是slope的置信区间从纳秒换算成微秒:10823.71 ns → 10.824 µs、10862.83 ns → 10.863 µs、10896.63 ns → 10.897 µs。
2.4 tukey.json——离群点判定边界
Criterion.rs 使用 Tukey(图基)方法把样本分成四个区域,对应四条 fence(围栏):
1 | { |
这四个值把样本空间切成五段(单位:纳秒):
1 | 严重偏低 轻微偏低 正常范围 轻微偏高 严重偏高 |
如果某个样本的平均耗时落在 high_severe(严重偏高,10939.66 ns)右边,就会被标记为 “high severe”(严重偏高)离群点——这就是 CLI 输出里 Found 2 outliers ... 2 (20.00%) high severe 的来源。
重要:Criterion.rs 标记离群点但不丢弃它们。 被标记的样本仍然参与后续所有统计计算。这是有意为之——离群点可能是测量噪声,也可能是真实行为(比如 GC 暂停、CPU 降频),盲目丢弃可能掩盖问题。
2.5 change/estimates.json——和基线的对比
只有第二次运行(存在 base/ 目录)时才会生成,记录当前运行相对基线的变化:
1 | { |
这里的值是比例而非纳秒。point_estimate(点估计)0.004082 表示均值比基线慢了约 0.41%;lower_bound(下界)-0.005601 表示最多可能快了 0.56%。CLI 输出的 change: [-0.5601% +0.4082% +1.2134%] 就是把这些比例乘以 100 得到的百分数。
2.6 小结:从原始数据到 CLI 输出的完整链路
1 | cargo bench 执行 |
3. 架构与数据流
了解了产物之后,下一个问题是:Criterion.rs 内部是怎么一步步从你的 b.iter(|| ...) 走到最终的 JSON 文件和 CLI 输出的?
Criterion.rs 的执行路径可以分成四层:公开 API、运行计划、计时循环、统计报告。
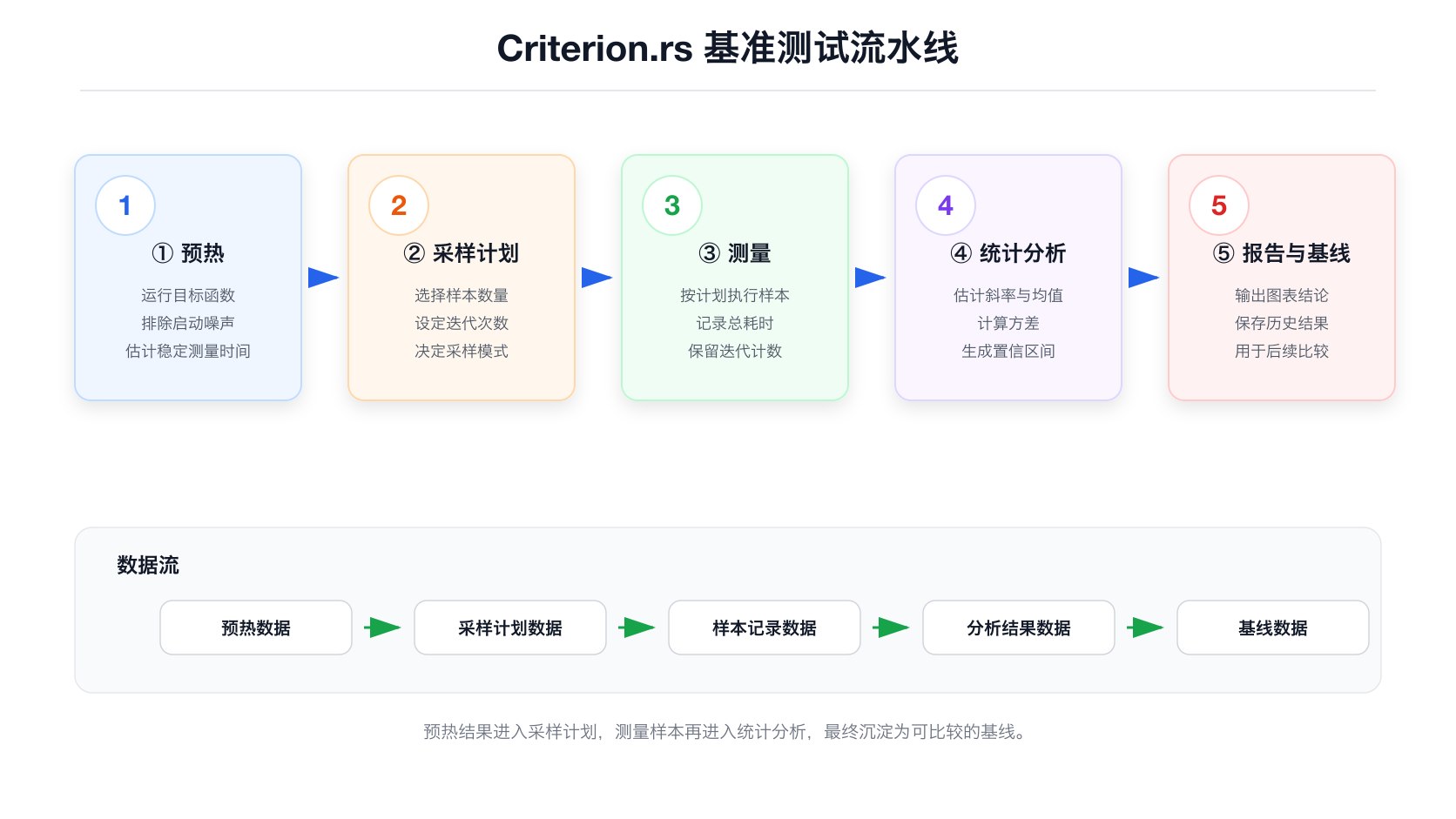
| 模块 | 职责 | 关键源码 |
|---|---|---|
| Macro harness | 把 benchmark 文件变成可执行入口 | src/macros.rs:61-80、src/macros.rs:115-127 |
| Public API | bench_function、benchmark_group、配置项 | src/lib.rs:1221-1271、src/benchmark_group.rs:96-234 |
| Benchmark dispatch | 生成内部 ID、合并配置、调用 analysis | src/benchmark_group.rs:272-326 |
| Routine sampling | warm-up、选择采样模式、生成迭代次数、执行样本 | src/routine.rs:85-207 |
| Timing loops | iter、iter_custom、iter_batched、iter_batched_ref | src/bencher.rs:83-141、src/bencher.rs:234-365 |
| Statistics(统计分析) | Tukey(图基)离群点分类、bootstrap(自助法)重采样、回归、估计构建 | src/analysis/mod.rs:140-157、src/analysis/mod.rs:274-343 |
| Baseline compare(基线对比) | t 检验、相对变化估计、噪声阈值(noise threshold) | src/analysis/compare.rs:15-76 |
4. 核心机制
接下来拆解 Criterion.rs 的五个核心机制。每个机制都按”解决什么问题→怎么实现→为什么这样设计→取舍”的结构展开。
4.1 机制一:自适应采样——用目标时间反推每个样本跑多少次
一句话理解: 函数快就多跑几次、函数慢就少跑几次,让总测量时间可控。
4.1.1 解决什么问题
微基准的函数耗时跨度很大:一个整数加法可能低于纳秒级,一个排序或压缩操作可能是毫秒级。固定”每个样本跑 100 次”会导致两个坏结果:超快函数的计时器开销占比过大,慢函数的基准运行时间失控。
Criterion.rs 的做法是先 warm-up,估计粗略单次耗时 met = warmup_elapsed / warmup_iters,再结合用户配置的 measurement_time 和 sample_size 生成每个样本的迭代次数。warm-up 以 1、2、4、8 的方式倍增迭代次数,直到累计时间超过配置值,见 src/routine.rs:285-309。
4.1.2 如何实现
普通模式下,Routine::sample 先报告 warm-up,再执行 warm-up,并计算 met:
1 | // src/routine.rs:136-170 (60ab5fd) |
SamplingMode::Auto 会先估算如果使用线性采样,总耗时是否超过目标时间的 2 倍;超过则切换到 Flat,否则使用 Linear,见 src/lib.rs:1386-1410。
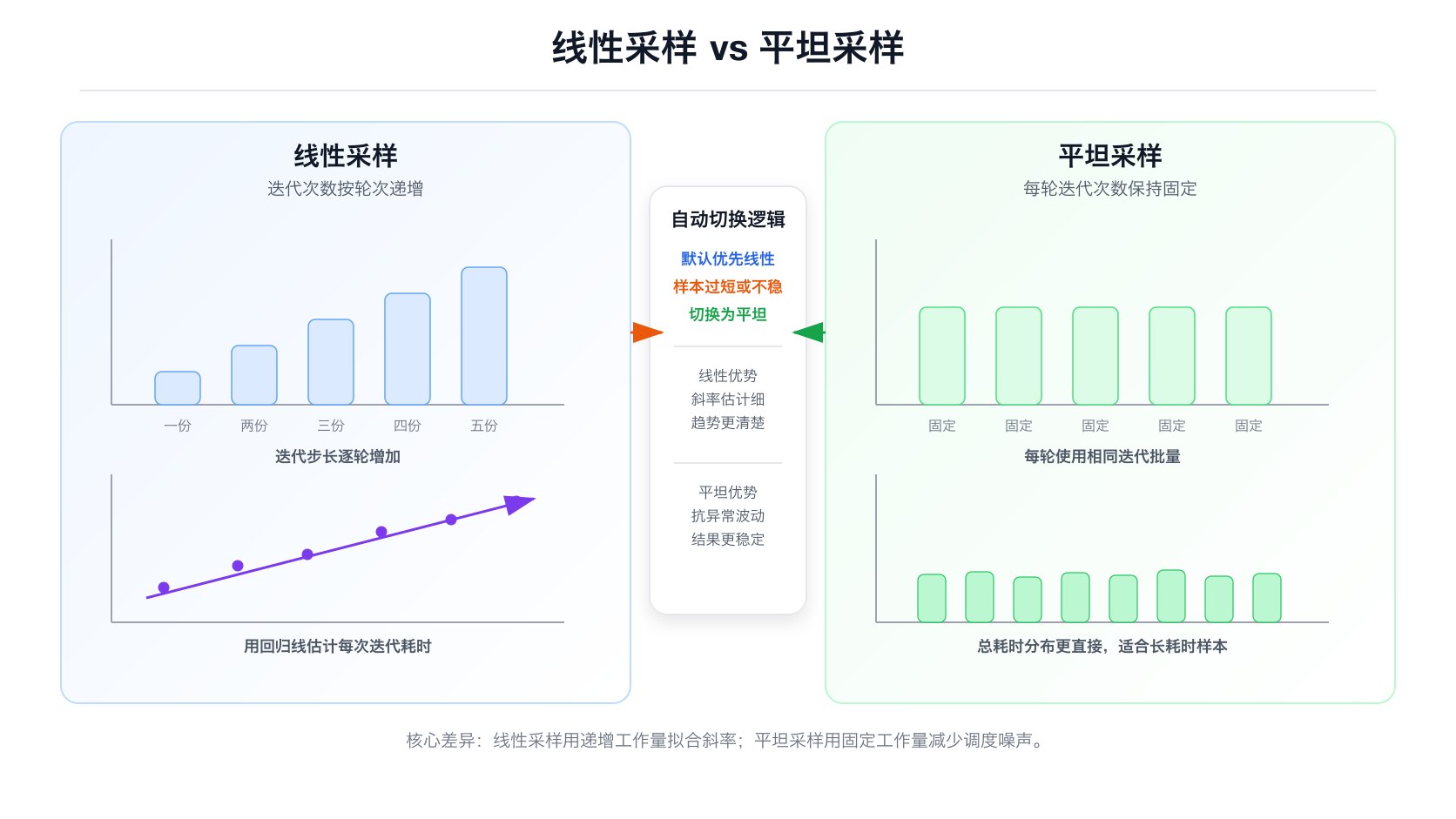
Linear 的迭代次数是 ,其中 的计算公式为:
这个公式的含义:总迭代次数 乘以单次耗时 ,应该接近目标测量时间。Section 2.2 用 fib 20 的实际数据做了完整的代入验算。源码在 src/lib.rs:1427-1455。
Flat 则把每个样本设置为相同的 iterations_per_sample,见 src/lib.rs:1456-1481。
4.1.3 为什么这样设计
线性采样有一个统计上的好处:当样本点是 (iters, elapsed) 时,被测函数的单次耗时可以建模为过原点直线的斜率。迭代次数逐步增加,能利用不同工作量的样本估计单位迭代的斜率(slope),降低固定噪声对典型估计(typical estimate)的影响。对于很慢的函数,Flat 牺牲一部分统计信息,换取可接受的总运行时间。
4.1.4 替代方案
替代方案是固定每个样本迭代次数,或者固定总迭代次数再均分。这种方式简单,但对不同耗时区间不自适应,也不容易给出”目标测量时间不足”的诊断。Criterion.rs 会在 d == 1 或 iterations_per_sample == 1 时提示增加目标时间或降低样本数,见 src/lib.rs:1437-1451 与 src/lib.rs:1466-1477。
4.1.5 Trade-off(取舍)
Linear 的样本质量更好,但总迭代次数是 N(N+1)/2 * d,默认 N = 100 时最少也有 5050 个迭代单位。Flat 更省时间,但源码明确标注它会影响 Criterion.rs 可计算的统计信息,公共枚举文档也不推荐除必要场景外使用,见 src/lib.rs:1379-1382。
4.1.6 动手验证:观察 Linear vs Flat
为了直观对比两种模式的差异,我们用同一个函数 fib(20) 分别强制指定 Linear 和 Flat,这样排除函数本身的干扰,只看采样策略的不同。
在 Section 1 的 fib-bench 项目里新建 benches/sampling.rs:
1 | // benches/sampling.rs |
在 Cargo.toml 追加:
1 | [[bench]] |
运行:
1 | cargo bench --bench sampling -- --noplot |
运行完后,检查两个 sample.json:
1 | cat "target/criterion/mode_linear/fib_20/new/sample.json" | python3 -m json.tool |
你会看到什么:
Linear 模式——iters 是公差为 的等差数列:
1 | "sampling_mode": "Linear", |
Flat 模式——iters 每个值都相同:
1 | "sampling_mode": "Flat", |
两者测出的 fib(20) 耗时几乎一样(~10.5 µs),但数据结构完全不同。Linear 的递增序列让 OLS(普通最小二乘法)线性回归能拟合出高质量的斜率估计;Flat 的等值序列则直接取每次测量的均值,跳过了回归步骤。
实际场景中你不需要手动指定模式。
SamplingMode::Auto(默认值)会自动判断:如果线性采样的总耗时超过目标时间的 2 倍,就切换到 Flat;否则用 Linear。这个 demo 的目的是让你在 JSON 层面直观看到两种模式的结构差异。
4.2 机制二:计时循环——把”测什么”交给用户,但把”怎么收样本”留在框架里
一句话理解: 框架决定跑多少次、怎么统计;你决定”开始计时”和”停止计时”之间包含哪些代码。
4.2.1 解决什么问题
微基准里最常见的错误是把不该测的东西测进去。例如排序 benchmark 如果每轮都需要克隆输入,克隆成本不应该算入排序;返回大对象时,析构成本可能污染函数耗时;外部进程或线程池场景则无法由框架简单包一层 Instant::now() 解决。
4.2.2 如何实现
Bencher 存储当前样本的 iters、测量对象、累计测量值和 warm-up 用的 elapsed_time,结构定义在 src/bencher.rs:40-46。Routine::bench 会为每个样本设置 b.iters,调用用户闭包,并要求它必须调用 Bencher::iter 或相关方法,见 src/routine.rs:239-282 与 src/bencher.rs:368-376。
最简单的 iter 只在整个循环前后做一次测量:
1 | // src/bencher.rs:83-96 (60ab5fd) |
iter_custom 则把迭代次数交给用户闭包,并要求闭包返回 Measurement::Value,见 src/bencher.rs:132-141。
4.2.3 为什么这样设计
Criterion.rs 把职责切得很清楚:框架负责规划样本、保存数据和统计分析[2];用户负责选择贴合被测对象的计时循环(timing loop)[3]。这样可以在同一套统计模型下覆盖纯函数、消耗输入的函数、返回大对象的函数、外部进程和自定义测量(measurement)。
4.2.4 Trade-off(取舍)
这种设计要求 benchmark 作者理解不同计时循环的测量模型。选错计时循环不会让 Criterion.rs 崩溃,却会给出”统计上自洽但语义错误”的结果。比如把每次迭代的准备工作(per-iteration setup)放在 iter 里,统计层仍然会认真分析,但分析的是 setup + routine 的总和。
4.2.5 动手验证:clone 开销去哪了?
这个 demo 同时覆盖机制二(计时循环)和机制三(批处理隔离)。关键思路:先单独测 clone 的开销,再对比”clone + sort”和”仅 sort”,让读者亲眼验证消失的那部分时间确实是 clone。
新建 benches/timing_loops.rs:
1 | // benches/timing_loops.rs |
在 Cargo.toml 追加:
1 | [[bench]] |
运行:
1 | cargo bench --bench timing_loops -- --noplot |
预期输出类似:
1 | sort_10000/clone_only time: [780.92 ns 786.60 ns 791.72 ns] |
你会看到什么:
clone_only≈ 0.79 µs——单次 clone 10000 个u64的成本(通过iter测量,实际包含 clone + drop;对Vec<u64>而言 drop 成本很低,可忽略)wrong_clone_inside_iter≈ 4.88 µs = clone + sort + dropright_iter_batched≈ 3.65 µs ≈ 仅 sort(setup 中的 clone 和结束后的 drop 均不计时)- 差值 4.88 − 3.65 = 1.23 µs,与
clone_only的 0.79 µs 量级吻合(不完全相等,因为iter中 clone、sort、drop 共享缓存行会产生额外交互开销)
三个数字的关系是近似的:wrong ≈ right + clone_only。对比代码可以看到,clone 没有消失——它从 iter 闭包内部移到了 iter_batched 的 setup 参数里,从而被排除在计时窗口之外。
这个 demo 直观说明了一个核心原则:选错计时循环不会报错,但会让你测到错误的东西。
4.3 机制三:批处理隔离——在 setup、routine、drop 之间划清边界
一句话理解: 排序要测的是排序本身,不是”克隆一个数组 + 排序 + 释放结果”的总和。批处理让你把准备和清理从计时窗口中拿出去。
4.3.1 解决什么问题
很多微基准不是纯函数——排序需要未排序输入,解析器可能需要新 buffer,某些返回值析构很贵。要准确测 routine 本身,就必须把准备(setup)和清理(drop)从计时窗口中移出去。
简单来说:iter_batched 把 setup 移到计时外,routine 拿到输入的所有权(ownership);iter_batched_ref 更进一步,routine 只拿 &mut 引用,输入的 drop 也在计时窗口之后执行。如果输入的析构(drop)本身很贵且你不想测它,选 iter_batched_ref。
4.3.2 如何实现
iter_batched 先通过 BatchSize::iters_per_batch 决定批大小,再在每一批中先生成 inputs,随后只把 routine 的执行包在 measurement.start() 与 measurement.end() 之间,最后把 outputs 延后处理,见 src/bencher.rs:234-278。需要注意的是,iter_batched 会把被消耗 input 的所有权传给 routine;如果 input 的析构语义会混入你不想测的部分,iter_batched_ref 更合适,因为它让 routine 接收 &mut I,并在计时窗口之后显式 drop input,见 src/bencher.rs:322-365。
BatchSize 给出五种策略:
| 策略 | 批大小计算 | 适用场景 |
|---|---|---|
SmallInput | iters.div_ceil(10) | 默认优先;输入和输出小 |
LargeInput | iters.div_ceil(1000) | 降低内存占用,增加少量测量开销 |
PerIteration | 1 | 输入或输出极大,或持有有限外部资源 |
NumBatches(n) | iters.div_ceil(n) | 手动控制批次数 |
NumIterations(n) | n | 手动固定每批迭代数 |
计算逻辑在 src/lib.rs:233-248。
4.3.3 为什么这样设计
批处理的目标是减少每次 start/end 的固定开销,同时避免一次性持有过多输入和输出。Criterion.rs 的文档给了粗略开销量级:SmallInput 约 500 ps、LargeInput 约 750 ps、PerIteration 约 350 ns,源码注释强调这些数字只是选择指南,不能从测量值里机械扣除,见 src/lib.rs:180-189 与 src/lib.rs:193-217。
4.3.4 Trade-off(取舍)
批越大,计时器调用越少,测量开销(measurement overhead)越低,但内存占用越高,也可能改变缓存行为。批越小,语义隔离越强,内存风险越低,但开销占比变大。PerIteration 语义最干净,性能测量最贵。
4.4 机制四:bootstrap 与回归——从样本构造置信区间
一句话理解: 不相信单次运行的”平均值”,而是通过反复随机重采样来估计”真实值大概率落在哪个范围”。
4.4.1 解决什么问题
单次 benchmark 的均值很脆弱。操作系统调度、CPU 频率、后台进程、缓存状态都会制造波动。Criterion.rs 需要回答的是”真实总体参数大概率落在哪个区间”,而不是”这 10 或 100 个样本的平均数是多少”。
Section 2.3 已经用 fib 20 的实际数据演示了自助法(bootstrap)的基本过程(有放回抽样 → 算均值 → 重复 1000 次 → 排序取边界)。这一节聚焦 Criterion.rs 在源码层面是怎么做的,以及它对斜率(slope)的自助法有什么不同。
4.4.2 如何实现
分析阶段先把 (iters, times) 转成 avg_times,然后分三步:
第一步:Tukey 离群点分类
用 Tukey 方法标记离群点(但不丢弃),见 src/analysis/mod.rs:140-149。
第二步:对均值(mean)、中位数(median)、标准差(std_dev)、中位数绝对偏差(MAD)做自助法重采样
对 avg_times 做 次有放回重采样( 就是 nresamples(重采样次数),默认 100,000),每次算出均值、中位数等统计量。最终得到每个统计量的 个值,从中取分位数构造置信区间。见 src/analysis/mod.rs:305-343。
第三步:对斜率(slope)做自助法重采样(Linear 模式专属)
第二步对 avg_times(每个样本的平均耗时)做自助法,得到均值、中位数等标量统计量的置信区间。但斜率不是标量统计量——它来自 两个变量的关系,所以需要不同的重采样策略。
斜率的自助法不是简单地对 avg_times 重采样,而是对 这对数据做成对重采样(paired resampling):每次从 10 个 点里有放回抽 10 对,重新拟合过原点直线,得到一个斜率。重复 次,得到斜率的分布。
1 | 原始数据: 10 个 (iters, times) 点 |
见 src/analysis/mod.rs:151-157 与 src/analysis/mod.rs:274-303。
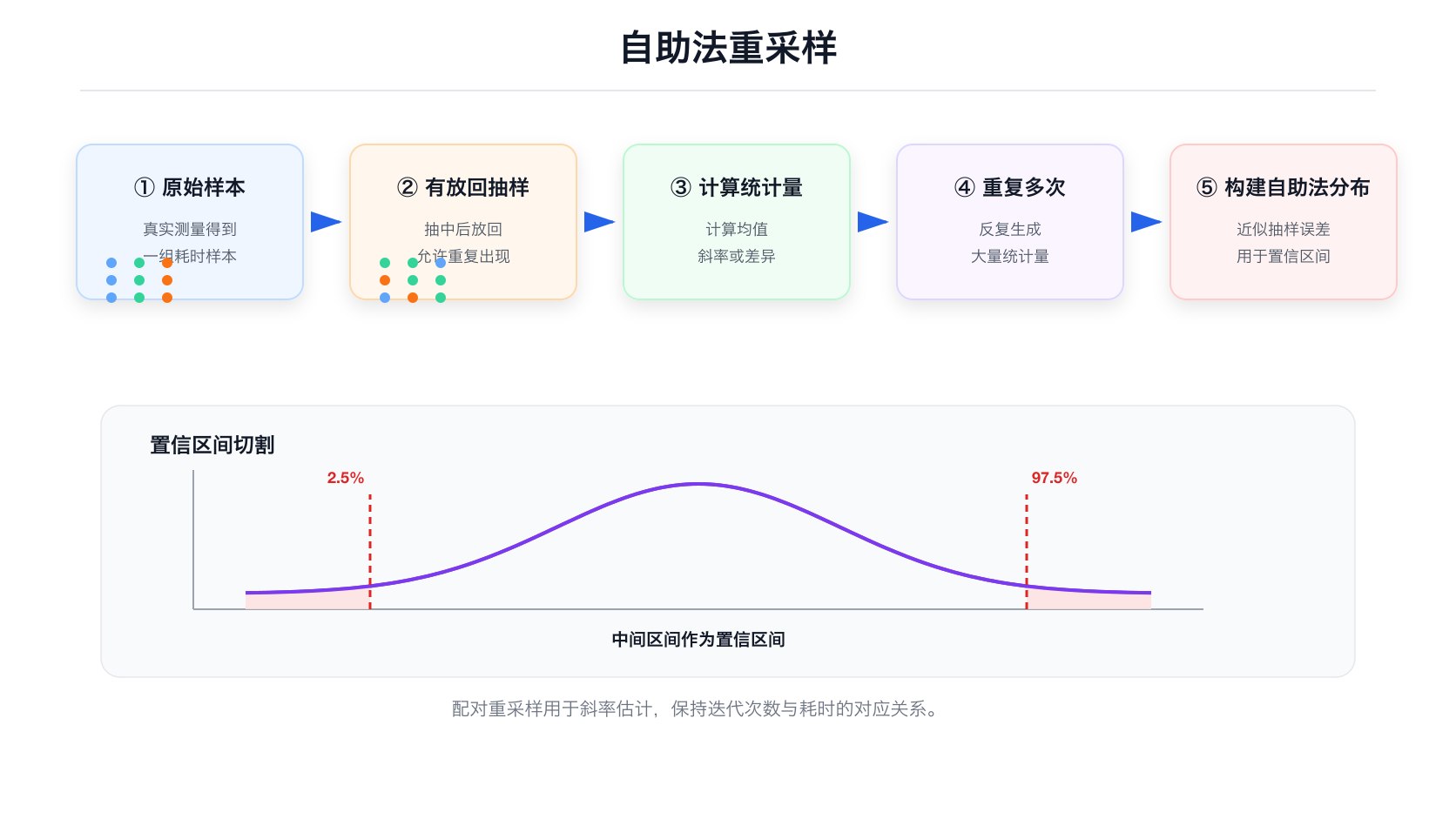
置信区间的取法很直接——从自助法分布的分位数切割:
1 | // src/stats/mod.rs:40-56 (60ab5fd) |
OLS(普通最小二乘法)过原点回归的斜率公式是:
其中 是每个样本的迭代次数, 是对应的总耗时。对应源码:
1 | // src/stats/bivariate/regression.rs:16-28 (60ab5fd) |
用 fib 20 的实际数据代入验算:
这和 estimates.json 里 slope.point_estimate(斜率的点估计)= 10862.83 一致。Section 2.2 的散点图中,红色回归线的斜率就是这个值。
4.4.3 为什么这样设计
自助法避免了为微基准耗时分布强行假设正态分布。回归斜率则利用了线性采样的额外结构:如果每个样本跑的迭代次数不同,那么总耗时和迭代次数之间的关系比单纯 elapsed / iters 更有信息量(Section 2.2 的散点图直观展示了这一点)。
4.4.4 Trade-off(取舍)
默认 nresamples = 100000 让置信区间更稳定,但分析时间也更长;源码在把 nresamples 降到 1000 或以下时会警告,见 src/benchmark_group.rs:133-151。另外,bootstrap 仍然无法修复错误的 benchmark 语义;如果样本测到的是 setup + routine,置信区间只会更精确地描述错误对象。
4.4.5 动手验证:样本数如何影响置信区间
不需要新建文件。回到 Section 1 的 benches/fib.rs,分两轮运行来对比。
第一轮:少样本 + 少重采样
确保 fib.rs 里的配置是:
1 | .sample_size(10) |
1 | cargo bench --bench fib -- --noplot |
记录输出的 CI 宽度,例如:
1 | fib 20 time: [10.651 µs 10.846 µs 11.038 µs] |
第二轮:恢复默认配置
把配置改成 Criterion.rs 的默认值(四个参数全部调高):
1 | .sample_size(100) |
1 | cargo bench --bench fib -- --noplot |
1 | fib 20 time: [11.079 µs 11.144 µs 11.213 µs] |
你会看到什么:
- 第二轮的置信区间窄了约 3 倍(从 ~387 ns 缩小到 ~134 ns)
- 点估计(中间的数字)两轮接近,但第二轮的”不确定性”小得多
- 代价是运行时间从不到 1 秒变成约 8 秒
这里同时改了四个参数(sample_size、nresamples、measurement_time、warm_up_time),所以无法精确归因于某一个。其中 sample_size(物理样本数)对置信区间宽度的影响最大——更多独立样本直接降低标准误差;nresamples 则让自助法分布更平滑;measurement_time 和 warm_up_time 保证每个样本的测量质量。总的来说:更充分的配置 → 更窄的置信区间 → 更有把握的结论,但需要更长的运行时间。
4.5 机制五:基线对比——把”变快/变慢”变成统计判定
一句话理解: “这次比上次慢了 0.3%“——是真的变慢了,还是系统噪声?用假设检验来回答。
4.5.1 解决什么问题
性能变化很容易被误判。一次运行比上次慢 0.3%,可能是真回归,也可能只是系统噪声。Criterion.rs 的比较阶段要同时回答两个问题:差异是否统计显著,以及差异是否大到值得报告。
4.5.2 如何实现
如果存在基线目录,analysis::common 会调用 compare::common,加载 base/sample.json 和 base/estimates.json,见 src/analysis/mod.rs:183-220。比较逻辑在 src/analysis/compare.rs:15-76。
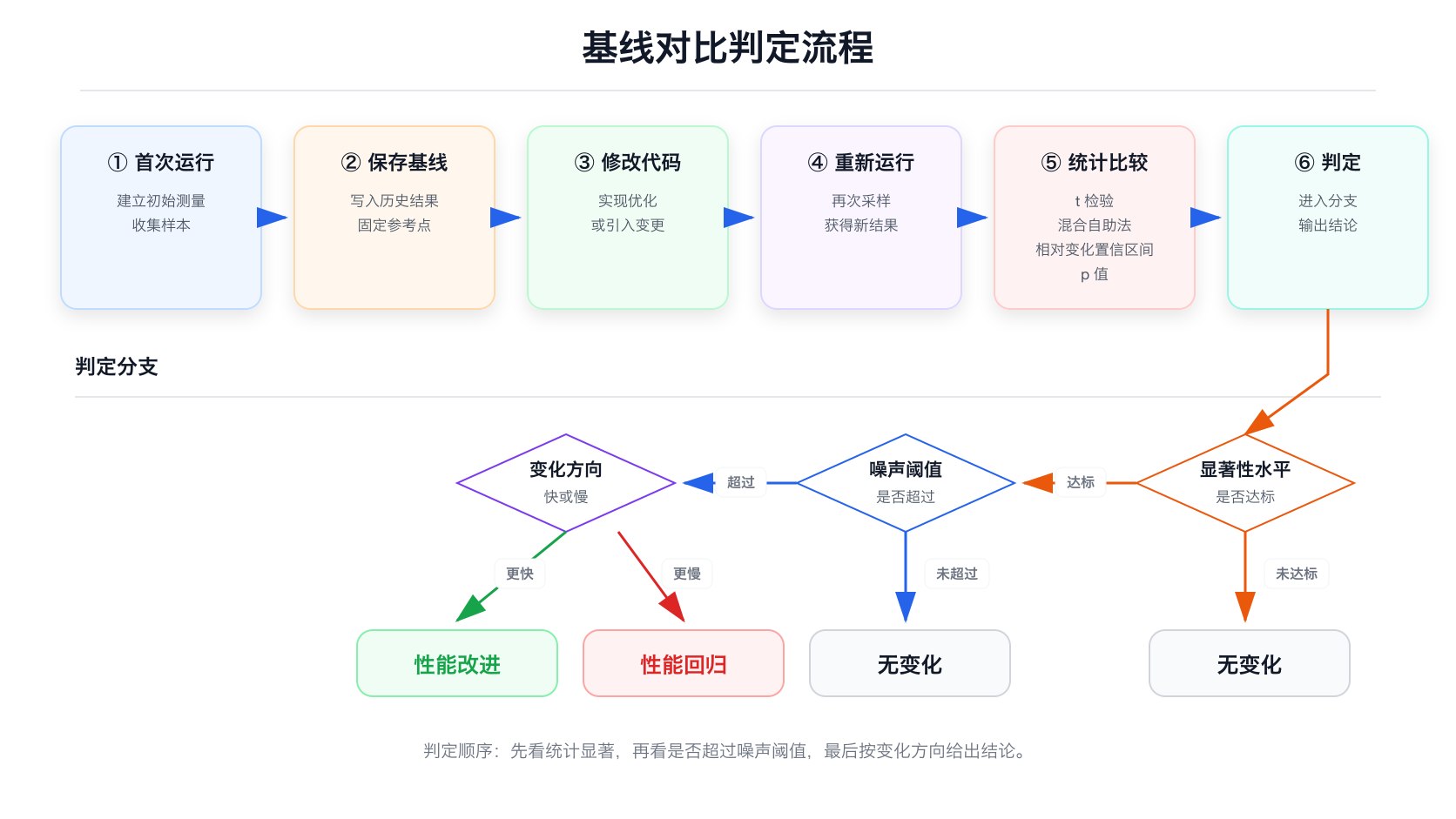
t_test 先计算当前样本与基线样本之间的 t 统计量(t statistic),再对两组样本做混合自助法(mixed bootstrap)得到 t 分布(t distribution),最后算双侧 p 值(two-tailed p-value):
1 | // src/analysis/compare.rs:78-104 (60ab5fd) |
Sample::t 计算的是 Welch 风格的 t 统计量(两组均值差除以两组方差按样本数缩放后的平方根),但 p 值不是从 t 分布表查出的,而是通过上面的混合自助法得到,见 src/stats/univariate/sample.rs:168-180。
4.5.3 为什么这样设计
Criterion.rs 把统计显著性和工程显著性分开。significance_level(显著性水平)控制 p 值阈值,默认 0.05;noise_threshold(噪声阈值)控制小变化过滤,默认 0.01,也就是 1%,见 src/lib.rs:413-420。这能避免”统计显著但工程上没意义”的微小抖动频繁污染报告。
4.5.4 Trade-off(取舍)
更低的显著性水平能减少误报,但会降低发现小真实变化的能力;更高的噪声阈值能让报告更安静,但也可能吞掉真实的小回归。Criterion.rs 的公开配置文档直接把这视为取舍,见 src/benchmark_group.rs:191-216。
4.5.5 动手验证:制造一次性能回归
用 Section 1 的 benches/fib.rs 来模拟”代码改动导致性能回归”的场景。
第一步:建立基线
确保 fib.rs 里测的是 fib 20,保持 Section 1 中的配置(sample_size(10) 等)不变,运行两次(让基线稳定):
1 | cargo bench --bench fib -- --noplot |
第二次的输出应该显示 “No change in performance detected.”。
第二步:故意变慢
把 bench_fibonacci 里的 20 改成 21:
1 | c.bench_function("fib 20", |b| b.iter(|| fibonacci(black_box(21)))); |
注意:benchmark 名字保持 "fib 20" 不变——这样 Criterion.rs 会拿 fib(21) 的结果和 fib(20) 的基线对比。
1 | cargo bench --bench fib -- --noplot |
预期输出:
1 | fib 20 time: [17.642 µs 17.713 µs 17.828 µs] |
你会看到什么:
change行显示约 +58% 的性能回归(具体百分比每次运行会略有不同;理论上 fib(21) ≈ fib(20) × φ ≈ 1.618,即约 +62%,实际受测量噪声影响)p = 0.00是 Criterion.rs 保留两位小数的显示截断,实际 p 值极小但不是精确的零- Criterion.rs 明确判定 “Performance has regressed.”
对比 Section 1.6 第二次运行时的 “No change in performance detected.”——同一套统计流程,面对噪声判定”没变”,面对真实回归判定”变慢了”。这就是基线对比的价值。
记得改回来: 验证完后把 21 改回 20。
5. 执行路径追踪:bench_function("fib 20", ...) 从入口到报告
前面分别讲了五个机制,这里用一条完整的调用链把它们串起来——从你写的 c.bench_function("fib 20", ...) 开始,一直追踪到 CLI 打出结果。
criterion_main!(benches)展开成main(),调用benches(),最后调用Criterion::default().configure_from_args().final_summary(),见src/macros.rs:115-127。criterion_group!完整形式构造用户配置的Criterion,再把可变引用传给 target 函数,见src/macros.rs:61-72。Criterion::bench_function创建一个同名BenchmarkGroup,再调用组内bench_function,见src/lib.rs:1221-1227。BenchmarkGroup::run_bench合并配置、生成内部 ID、处理过滤器,然后在Mode::Benchmark下进入analysis::common,见src/benchmark_group.rs:272-326。analysis::common调用routine.sample收集样本;如果连接了cargo-criterion,会发送消息并返回,否则继续本地分析,见src/analysis/mod.rs:63-110。routine.sample完成 warm-up、采样模式选择、迭代次数规划和真实测量,见src/routine.rs:136-207。Function::bench对每个样本设置b.iters,调用用户闭包|b| b.iter(...),并把 measurement value 转成f64,见src/routine.rs:239-282。Bencher::iter在循环前后调用measurement.start/end,循环内部用black_box阻止优化,见src/bencher.rs:83-96。analysis::common对样本做 Tukey、bootstrap、回归、保存 JSON、基线对比并触发报告,见src/analysis/mod.rs:112-244。
6. Runtime 与内部细节
这一节是进阶内容,介绍三个对理解 Criterion.rs 行为有帮助但不影响日常使用的内部细节。
6.1 Measurement trait:时间只是默认测量单位
默认 measurement 是 WallTime,但 Criterion.rs 的 measurement 层是 trait:
1 | // src/measurement.rs:73-100 (60ab5fd) |
WallTime 的 Intermediate 是 Instant,Value 是 Duration,最后转成纳秒 f64,见 src/measurement.rs:237-260。这解释了为什么 iter_custom 可以用于外部进程:只要闭包返回 M::Value,统计层不关心这个值来自哪里。
6.2 alloca:轻微扰动栈布局以降低缓存/对齐偏差
Criterion.rs 提供了可选的 alloca feature(需显式启用),启用后 Function::bench 在支持平台上会按样本索引变化 stack allocation size,源码注释说明目的是降低 memory alignment 与 cache effects 的测量偏差,见 src/routine.rs:252-269。对应 feature 在 Cargo.toml:88-95。
6.3 离群点(Outlier)不会被丢弃
Criterion.rs 会分类离群点并报告,但不会把它们从后续统计中移除。官方文档也明确说明离群样本仍会参与后续分析。源码上,labeled_sample 被放进 MeasurementData.avg_times,但 estimates(avg_times, config) 仍使用原始 Sample,见 src/analysis/mod.rs:140-157。
7. 性能与取舍
| 设计点 | 优化了什么 | 代价 |
|---|---|---|
| warm-up 倍增 | 快速估计单次耗时,避免冷启动污染 | warm-up 本身增加运行时间 |
| Linear sampling | 支持斜率回归,样本信息更多 | 慢 benchmark 的总迭代数可能很大 |
| Flat sampling | 控制长耗时 benchmark 的总时间 | 无法使用斜率(slope)作为典型估计 |
iter | 每个样本只做一次 start/end,开销最低 | setup/drop 容易混入计时 |
iter_batched | 隔离 setup(准备工作),降低每次迭代的计时开销 | 批大小会影响内存与缓存行为 |
PerIteration | 语义隔离最强,内存占用最低 | 粗略开销量级约 350 ns |
| 自助法(bootstrap)默认 100,000 次重采样 | 置信区间更稳定 | 分析时间和内存随重采样次数增长 |
| 噪声阈值(noise threshold)默认 1% | 减少小噪声误报 | 可能掩盖真实的小幅性能变化 |
这套设计的核心偏好是:把被测代码的执行时间花足,换取统计结果的可解释性。它不适合”随手跑一下看看大概”的极轻量场景,但适合把微基准纳入持续性能回归判断。
8. 与其他基准方法对比
| 维度 | Criterion.rs | Cargo/libtest bench | iai-callgrind | hyperfine |
|---|---|---|---|---|
| 主要对象 | Rust 函数/代码片段 | Rust benchmark harness | Rust 函数/二进制的指令级指标 | 任意 shell 命令 |
| 稳定 Rust | 支持 | #[bench] 依赖 nightly;Cargo 支持自定义 harness | 支持,但依赖 Valgrind/平台 | 支持,语言无关 |
| 核心方法 | 预热 + 采样 + 自助法 + 回归 | libtest harness 运行 benchmark | Callgrind/Cachegrind 指令和缓存模拟 | 多次运行命令,做统计汇总 |
| 抗系统噪声 | 通过重复测量和统计估计缓解 | 较弱 | 很强,尤其适合 CI 的确定性指标 | 取决于命令和环境,可配置 warm-up |
| 能否测真实 wall time | 是 | 是 | 主要是模拟/计数指标,不等同真实 wall time | 是 |
| 最适合 | 库函数、算法、吞吐、回归检测 | 简单 nightly benchmark | 噪声环境下的细粒度回归检测 | CLI、端到端命令、跨语言工具比较 |
对比依据来自主资料:Cargo Book 对 cargo bench 与 custom harness 的说明[4]、iai-callgrind 对 Callgrind/Cachegrind 方法的说明[5],以及 hyperfine 对命令行 benchmark 的定位[6]。Criterion.rs 与这些工具不是互斥关系:库函数微基准优先 Criterion.rs,CI 噪声很重且更关心指令数时考虑 iai-callgrind,端到端 CLI 则用 hyperfine 更自然。
8.1 离群点(Outlier)处理最佳实践横向对比
什么是离群点(Outlier)? 就是测量结果中”异常偏高或偏低”的数据点。比如 10 个样本里 9 个是 ~11 µs,有 1 个突然变成 50 µs——这个 50 µs 就是离群点。它可能是操作系统刚好调度了别的任务,也可能是 CPU 降频,也可能是你的函数确实偶尔会慢。
离群点没有一个跨工具通用的”删或不删”答案。正确问题应该先变成:离群点是测量污染、运行时阶段行为、输入真实长尾,还是 benchmark 本身写错了?不同工具的默认策略其实体现了不同的实验哲学[7-15]。
| 工具 | 默认立场 | Outlier 如何处理 | 更稳妥的实践 | 不该机械套用默认值的场景 |
|---|---|---|---|---|
| Criterion.rs | 标注但保留 | 使用改良 Tukey(图基)围栏分类轻微/严重离群点,后续估计仍使用原始样本 | 增加测量时间,检查 CPU 频率调节、后台任务、输入分布;保留 target/criterion 原始产物 | 如果大量离群点来自真实长尾,不应通过调整阈值把它”调没” |
| BenchmarkDotNet | 默认移除上侧 outlier | OutlierMode.RemoveUpper 是默认值;也可设为 DontRemove、RemoveLower 或 RemoveAll | CPU-bound 微基准可接受默认值;报告 outlier 策略,并在需要时加入 percentile 或完整统计列 | 网络、锁竞争、GC 暂停、磁盘、真实尾延迟是目标信号时,应使用 DontRemove 并报告 percentiles |
| Google Benchmark | 重复运行与方差控制优先 | 文档强调 repetitions 后报告 mean、median、stddev、CV,并保留 repeated run 输出 | 用 --benchmark_repetitions 增加重复次数;先按官方指南降低 CPU 调频、后台任务、SMT 等外部方差 | 只拿一次 run 的 mean 断言性能变化,尤其在 CV 较高时 |
| JMH | 用 JVM 隔离流程处理噪声 | 通过 warmup、measurement、fork、error/confidence interval 和 raw data 表示 JVM benchmark 的不确定性 | 单独项目运行,使用足够 warmup/fork,结合 profiler 判断 JIT、GC、OS 抖动 | 把 JVM outlier 直接当作可删除脏数据;它可能正是 GC 或 JIT 阶段切换 |
| pyperf | 警告、分析、调优,不静默删除 | pyperf stats 会统计 outlier;文档建议用更多 run/value/loop、pyperf system tune、hist/dump 分析 | 稳定不了时优先看 median 和 MAD;保留原始 JSON 方便复查 | 用 mean 覆盖不稳定分布,或在没有解释来源时删点 |
| hyperfine | 检测并提示环境干扰 | 提供统计 outlier detection;建议 quiet PC、--warmup、--prepare 等方式控制缓存和环境 | 对 CLI 用固定输入、固定准备命令、足够 runs;把 warning 当成复现实验的信号 | 外部进程、文件系统缓存、服务冷启动本来就是测量对象时,不能简单把慢 run 当污染 |
| pytest-benchmark | 暴露分布和比较指标 | 比较输出可选 min/mean 等指标;histogram 使用 modified Tukey box/whisker,min/max 作为 outlier 点展示 | 同时看 histogram、min、mean、stddev,不只看单个排序指标 | 图上出现长尾时只按 min 排名,会偏向”最好一次”而不是稳定表现 |
| iai-callgrind | 避开 wall-time outlier | 用 Callgrind/Cachegrind 指令和缓存模拟指标替代真实时间 | 在 CI 或嘈杂机器上作为 Criterion.rs 的互补指标,尤其适合细粒度回归 | 需要真实 wall time、尾延迟、系统调用或并发调度成本时,它不是替代品 |
版本说明: 以上对比基于各工具截至 2025 年中的稳定版本行为(Criterion.rs 0.8.x、BenchmarkDotNet 0.14.x、Google Benchmark 1.9.x、JMH 1.37+、pyperf 2.7.x、hyperfine 1.18.x、pytest-benchmark 5.1.x、iai-callgrind 0.14.x)。各工具的离群点策略可能随版本演进,请以对应版本文档为准。
这几套策略放在一起看,最佳实践可以压缩成五条:
- 先分类离群点的语义:测量噪声、合法长尾、运行时阶段变化、benchmark bug,处理方式完全不同。
- 如果判断是噪声,优先稳定环境、增加运行时间、增加样本或 repetitions,而不是先删点。
- 如果长尾是产品事实,保留离群点,并报告中位数、MAD(中位数绝对偏差)、分位数、直方图和最大值。
- 如果是纯 CPU-bound 微基准里的偶发上侧污染,BenchmarkDotNet 那类显式 trimming 可以接受,但必须暴露策略和被移除数量。
- CI 环境噪声不可控时,不要强行把 wall-time 结果包装成确定结论;用 iai-callgrind 这类 deterministic counters 补一条证据链。
9. Source Code Map
建议按下面顺序读源码:
| 顺序 | 文件 | 读什么 |
|---|---|---|
| 1 | src/macros.rs | criterion_group! 与 criterion_main! 如何接管 harness |
| 2 | src/lib.rs | 默认配置、SamplingMode、BatchSize、Throughput、顶层 API |
| 3 | src/benchmark_group.rs | 组级配置如何合并,benchmark ID 如何生成,何处进入 analysis |
| 4 | src/routine.rs | warm-up、sample plan、真实测量执行 |
| 5 | src/bencher.rs | 每种计时循环的测量边界 |
| 6 | src/measurement.rs | 自定义 measurement 如何插入 |
| 7 | src/analysis/mod.rs | 从样本到估计、报告、保存 baseline 的主流程 |
| 8 | src/analysis/compare.rs | 当前样本与基线样本如何比较 |
| 9 | src/stats/ | Sample、Distribution、bootstrap、Tukey、regression 的底层实现 |
10. 实践建议
- 默认从
b.iter(|| ...)开始。只有当 setup、drop、外部进程或异步运行时(runtime)真的影响语义时,再切换计时循环。 - 对会修改输入的 benchmark,用
iter_batched或iter_batched_ref,不要把clone()放进iter的闭包里。 SmallInput是大多数场景的起点;只有内存压力明显时才退到LargeInput或PerIteration。- 不要手写
for _ in 0..1000包在b.iter里面。这样会让 Criterion.rs 以为一次迭代是”一千次操作”,吞吐和估计语义都会变差。 - 看 CLI 输出时优先看区间而不是中位数字。
[lower estimate upper]的宽度比单个点估计更能说明 benchmark 是否稳定。 - 看回归(regression)/改进(improvement)时同时看 p 值和变化百分比。
p < 0.05只说明统计显著,不说明工程上重要。 - 如果离群点(outlier)很多,先检查机器环境、CPU 频率调节、后台任务、输入分布和 benchmark 是否太短,不要急着调低噪声阈值(
noise_threshold)。 - CI 上使用 Criterion.rs 时,尽量固定硬件、降低并发噪声,并保存完整
target/criterion产物;如果环境噪声不可控,考虑用 iai-callgrind[5] 作为互补指标。
11. 总结
Criterion.rs 的微基准方法可以概括为一句话:用执行计划减少计时误差,用计时循环(timing loop)明确测量边界,用自助法(bootstrap)和回归把有限样本转成带置信度的结论。
它没有承诺”每次都给你绝对真值”。相反,它承认微基准天然嘈杂,然后把噪声显式纳入流程:预热(warm-up)抵消冷启动,采样计划控制运行时间,Tukey(图基)方法标出离群点,自助法给出置信区间,基线对比(baseline compare)用 p 值和噪声阈值区分统计显著与工程显著。
这也是使用 Criterion.rs 时最重要的心智模型:你写的不是一个”计时器包装函数”,而是一份统计实验设计。被测代码、输入构造、计时循环、样本数量、目标时间和运行环境,都会成为结论的一部分。
版本与资料
源码版本:criterion-rs/criterion.rs commit 60ab5fd10cc41d5c43a421f982d6bd981d36d05f,包版本 0.8.2,本地描述 criterion-v0.8.2-14-g60ab5fd。
参考文献:
[1] Criterion.rs 源码. github.com/criterion-rs/criterion.rs
[2] Criterion.rs Book - Analysis Process. bheisler.github.io/criterion.rs/book/analysis.html
[3] Criterion.rs Book - Timing Loops. bheisler.github.io/criterion.rs/book/user_guide/timing_loops.html
[4] The Cargo Book - cargo bench. doc.rust-lang.org/cargo/commands/cargo-bench.html
[5] iai-callgrind - docs.rs. docs.rs/iai-callgrind
[6] hyperfine - docs.rs. docs.rs/crate/hyperfine/latest
[7] BenchmarkDotNet - Jobs and OutlierMode. benchmarkdotnet.org/articles/configs/jobs.html
[8] BenchmarkDotNet - Outlier sample. benchmarkdotnet.org/articles/samples/IntroOutliers.html
[9] BenchmarkDotNet - Statistics. benchmarkdotnet.org/articles/features/statistics.html
[10] Google Benchmark - User Guide. github.com/google/benchmark/blob/main/docs/user_guide.md
[11] Google Benchmark - Reducing Variance. google.github.io/benchmark/reducing_variance.html
[12] OpenJDK JMH. openjdk.org/projects/code-tools/jmh
[13] OpenJDK JMH Statistics source. github.com/openjdk/jmh
[14] pyperf - Analyze benchmark results. pyperf.readthedocs.io/en/latest/analyze.html
[15] pytest-benchmark - Comparing benchmarks. pytest-benchmark.readthedocs.io/en/latest/comparing.html

